


이 글은 FlashAttention-2(Tri Dao, ICLR ‘23)와 NVIDIA A100 Tensor Core GPU Architecture를 바탕으로, 커널 launch부터 Tensor Core 연산까지의 전체 실행 경로를 하나의 시나리오로 정리한 글이다.
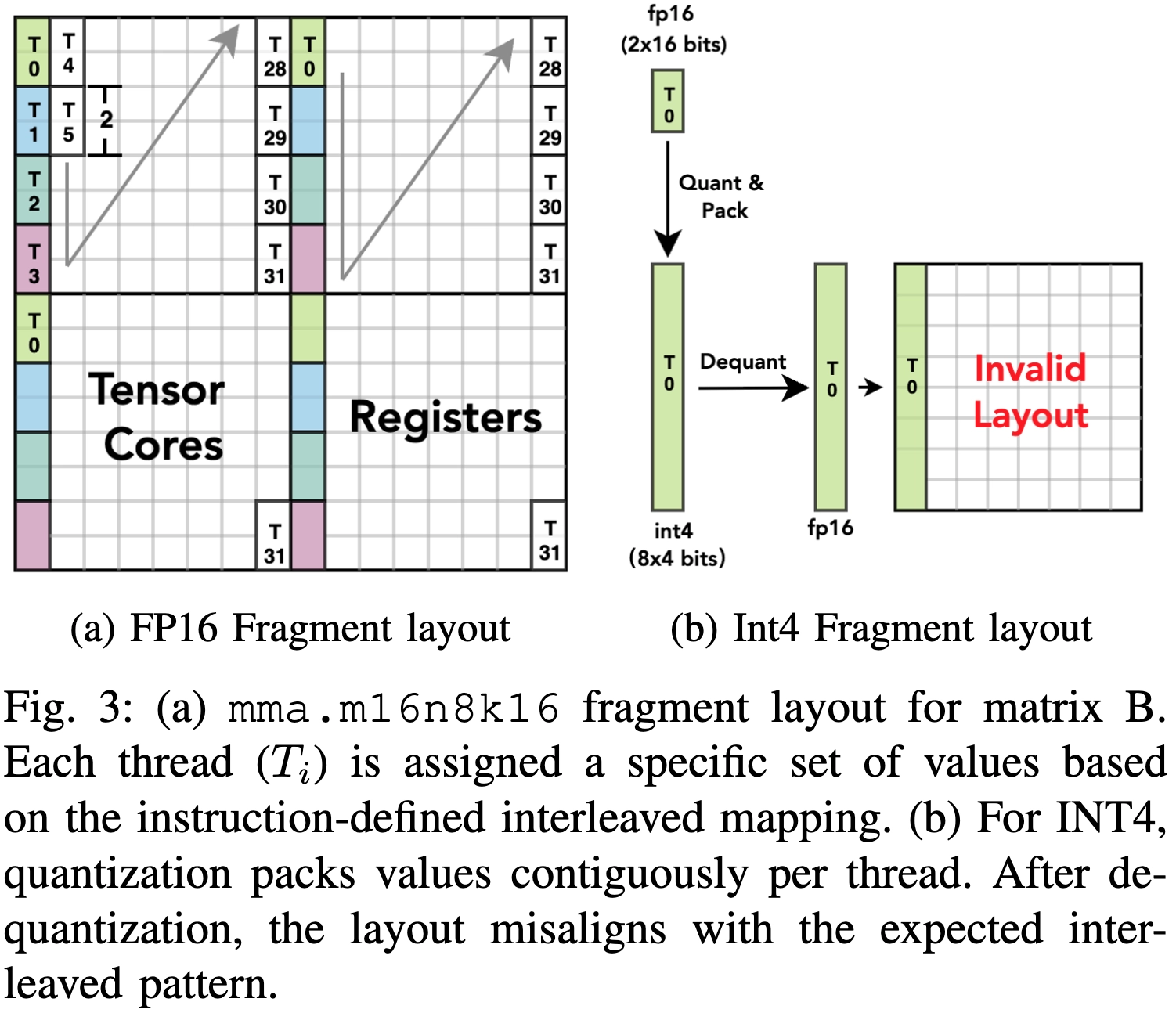
BitDecoding(HPCA ‘26) 논문을 읽다가 아래 Fig 3을 이해하지 못해서 Tensor Core가 어떤 식으로 동작하는지 공부하다가 정리한 글이다. Tensor Core가 어떤 식으로 동작하는지 알기 위해서 GPU가 어떻게 구성되어 있으며, 행렬을 어떤 식으로 나눠서 연산하는지 알아야만 했다. 시간은 조금 걸렸지만, BitDecoding의 Figure 3을 확실히 이해할 수 있었다.
kernel<<<grid, block>>>() 한 줄을 호출한 그 순간부터, GPU 안에서 Thread Block이 SM에 배정되고, Warp가 작업을 나누고, Tensor Core가 행렬을 곱하기까지의 전체 경로를 Top-Down으로 정리했다. Attention Kernel은 FlashAttention-2를 기준으로, 256x128 크기의 가 어떻게 Tile로 쪼개져 SM과 Warp, 그리고 Thread의 Register까지 흘러내려가는지를 숫자 예시와 함께 설명했다.
시작하기 전
추상적인 설명을 피하기 위해 처음부터 끝까지 하나의 구체적인 시나리오를 설정했고, 하드웨어는 GPU A100을 기준으로 한다.
항목 | 값 |
Q, K, V | 각 256×128 (N=256 시퀀스, d=128 head dim) |
타일 크기 | 128×128 (=128, =128) |
Q 타일 수 () | 256 / 128 = 2 |
K·V 타일 수 () | 256 / 128 = 2 |
MMA 명령 | m16n8k16 (FP16 입력, FP32 누적) |
데이터 타입은 FP16(2 bytes)을 가정한다.
이 시나리오에서 Grid는 Q 타일 2개에 대응하는 Thread Block 2개로 나뉜다. 최종 출력 O는 Q와 같은 shape인 256x128이 된다.
전체 흐름은 다음 세 부분으로 나눠 따라간다.
•
Part 1. 커널 Launch: CPU가 GPU에 커널을 전달하고 Grid가 SM에 분배되는 과정
•
Part 2. Thread Block과 Warp: FlashAttenton-2의 루프 구조와 작업 분할
•
Part 3. Warp 내부 연산: Tensor Core MMA와 Online Softmax
Part 1. 커널 Launch: CPU에서 GPU SM 분배까지
1-1. 커널 코드가 실행되기까지
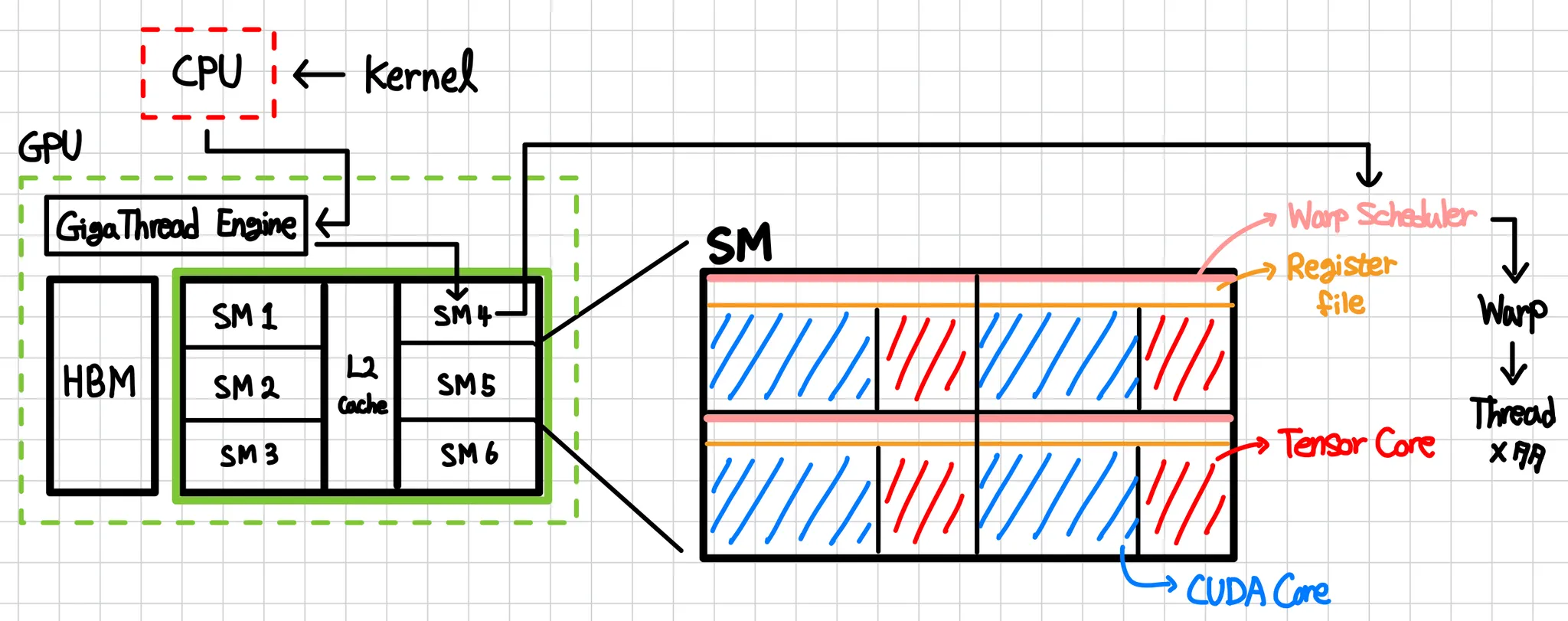
CPU부터 GPU 내부 구조 by 필자
GPU에서 실행될 커널 함수(__global__)는 CPU의 명령 스트림에 들어가지 않고 실제 동작은 다음과 같다.
커널은 컴파일 시 가상 GPU 어셈블리인 PTX(Parallel Thread Execution)를 거쳐 실제 GPU Instruction인 SASS(GPU 바이너리)로 변환되어, 프로그램이 로드될 때 GPU 메모리(HBM)에 적재된다. CPU가 실제로 실행하는 것은 커널 코드가 아니라, “이 커널을 이 Grid 크기로 실행하라”는 launch 지시 명령(kernel<<<grid,block>>>() 또는 cuLaunchKernel)이다. 커널 코드는 이미 GPU 쪽에 준비되어 있고, CPU는 HBM에 있는 그 커널 함수를 지정한 차원으로 실행하라고 지시할 뿐이다.
1-2. CPU 측 흐름
0. (사전) 커널 SASS가 HBM에 적재되어 있음
1. CPU가 host 코드 실행 → kernel<<<grid,block,smem>>>() 도달
2. CUDA Runtime API → Driver API cuLaunchKernel 호출
3. Driver가 launch 패킷을 pushbuffer(command buffer)에 기록
(grid/block 차원, 커널 주소, 인자 포인터, shared memory 크기 등)
4. Driver가 doorbell write — GPU host interface의 MMIO 레지스터에
"새 작업 있음" 신호를 기록
Plain Text
복사
Launch 패킷에는 커널 인저(QKV 포인터, 차원, 스칼라)도 함께 직렬화되어 들어간다. pushbuffer는 host-visible 메모리이고, doorbell write는 MMIO 레지스터를 통한 GPU 알림이다.
1-3. GPU 측 흐름
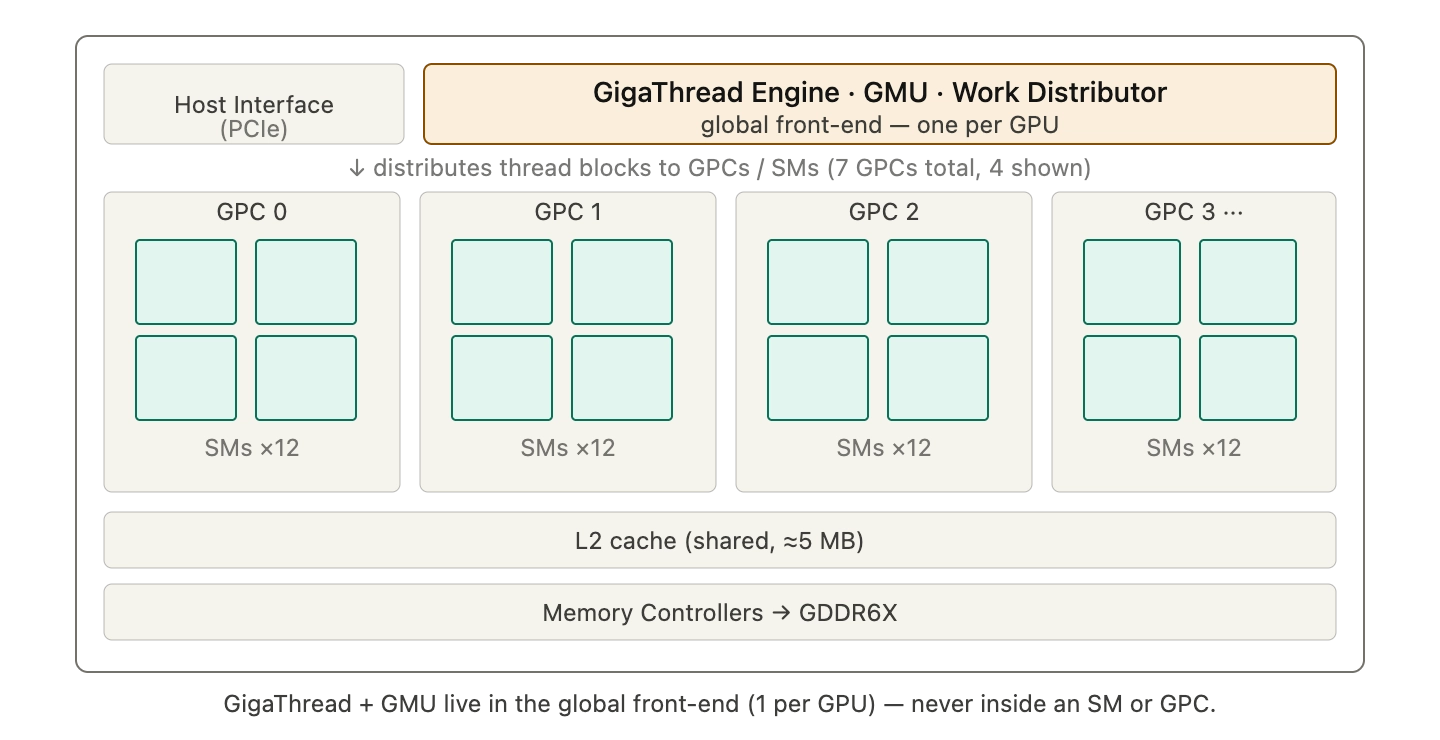
GPU 내부 구조 with GigaThread Engine by Claude
1. Host Interface가 doorbell 감지 → pushbuffer를 DMA로 읽음
2. "grid launch" 명령을 GigaThread Engine에 전달
3. CWD(Compute Work Distributor)가 block들을
"자원 여유 있는 SM"에 분배
4. 각 SM의 Warp Scheduler가 block을 warp(32 thread)로 분할
5. block 완료 → 대기 block을 자원이 난 SM에 투입 → grid 완료까지 반복
Plain Text
복사
각 유닛의 역할은 다음과 같다.
유닛 | 역할 |
GigaThread Engine | grid 전체를 받는 전역 스케줄러 |
CWD (Compute Work Distributor) | 실제 block → SM 할당 담당 |
Warp Scheduler (SMSP당 1개) | block을 warp로 나눠 명령 발행 |
CWD(Compute Work Distributor)가 Block이 비어 있는 SM이 아니라 자원이 충분한 SM을 할당한다. Register, Shared Memory, Warp slot이 남는 SM에 배정되며, 한 SM에 여러 block이 동시에 거주할 수 있다. 그리고 한 번 SM에 배정된 block은 끝날 때까지 그 SM에 머물며 다른 SM으로 옮겨지지 않는다. block이 끝나면 대기 중인 block이 그 자리를 채운다.
Part 2. Thread Block과 Warp: 루프 구조와 작업 분할
2-1. Grid → Thread Block 매핑 및 병렬 연산
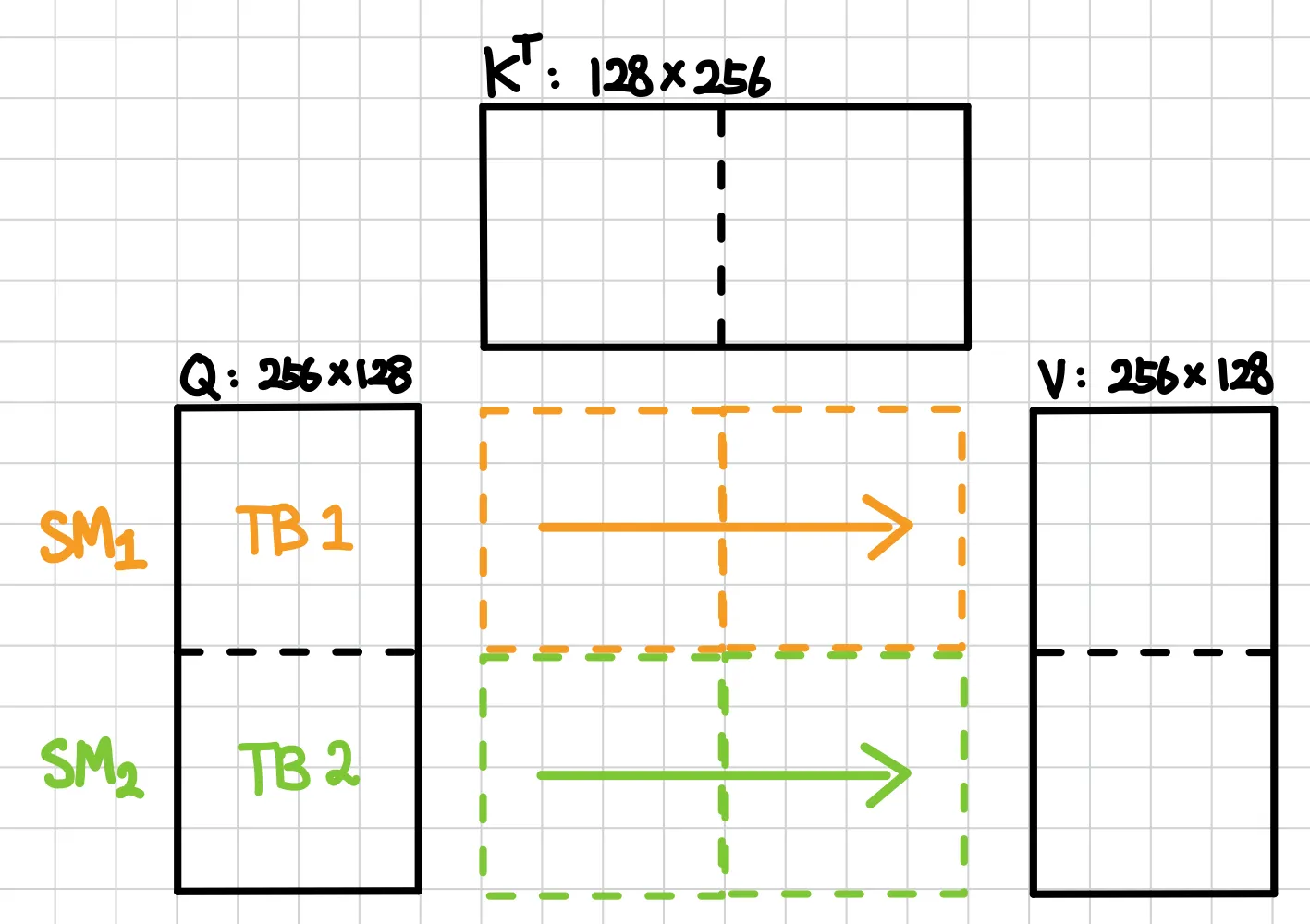
이 시나리오에서 Grid는 Q 타일 2개에 대응하는 Thread Block 2개로 나뉜다.
TB1 → Q_t1 (행 0–127) 담당 → inner loop: (K_t1,V_t1), (K_t2,V_t2)
TB2 → Q_t2 (행 128–255) 담당 → inner loop: (K_t1,V_t1), (K_t2,V_t2)
└ 서로 다른 SM에서 동시 실행 (통신 없음)
Plain Text
복사
여기서 어떻게 병렬로 처리되는지 처음에 이해되지 않았다. Outer loop의 Q를 Thread Block으로 병렬로 처리하고 각 Thread Block이 Inner loop를 처리한다. 각 Inner loop에서는 순차적으로 K, V의 tile들이 처리된다.
층위 | 무엇이 병렬인가 | 방식 |
TB 간 병렬 | Q_t1, Q_t2 (서로 다른 Q 타일) | 여러 SM에서 동시 실행 |
inner loop 순차 | K_t1 → K_t2 | 한 TB 내부에서 차례대로 |
Outer(Q)가 병렬 가능한 이유는 Q_t1과 Q_t2가 서로의 결과에 전혀 관여하지 않기 때문이다. Q_t1의 출력은 Q_t1과 모든 K, V로만 결정되므로, 각 Thread Block이 자기 출력 영역을 배타적으로 소유한다. 즉, 각 Q마다 통신이 필요 없어서 여러 SM에 분산하여 병렬 처리할 수 있다.
Inner(K, V)가 순차인 이유는 Online Softmax의 누적 의존성 때문이다. K_t1을 보고 누적 통계()를 업데이트한 뒤, K_t2에는 그 값을 이어받아 다시 업데이트한다. 이 의존성 때문에 순차적으로 처리할 수밖에 없다.
FlashAttention-2는 outer loop를 Q로 두어 각 Q 타일이 출력을 배타적으로 소유하도록 한다. 덕분에 sequence 차원으로 Thread Block을 쪼개서 Occupancy를 올릴 수 있다.
[참고] 중간 행렬을 HBM에 write하지 않음 (FlashAttention-2)
표준 Attention은 S = QKᵀ, softmax(S), O = PV 세 연산을 분리된 커널로 실행하며, 중간 행렬 S와 P(각 )를 HBM에 완전히 기록하고 다시 읽는다. 기준 S, P는 각 8MB이고, 관련 HBM 트래픽만 약 32MB에 달한다. 정작 의미 있는 입출력은 수 MB뿐이므로, 대부분의 시간이 거대한 중간 행렬을 느린 HBM에서 읽고 쓰는 데 소모된다.
FlashAttention-2는 이 연산들을 하나의 커널로 fuse한다. S 타일이 SRAM에 올라온 순간 HBM으로 내보지 않고 곧바로 online softmax와 누적까지 끝낸 뒤 HBM에 write한다. S와 P의 중간 결과가 HBM에 한 번도 write되지 않아서 속도 향상으로 이어진다.
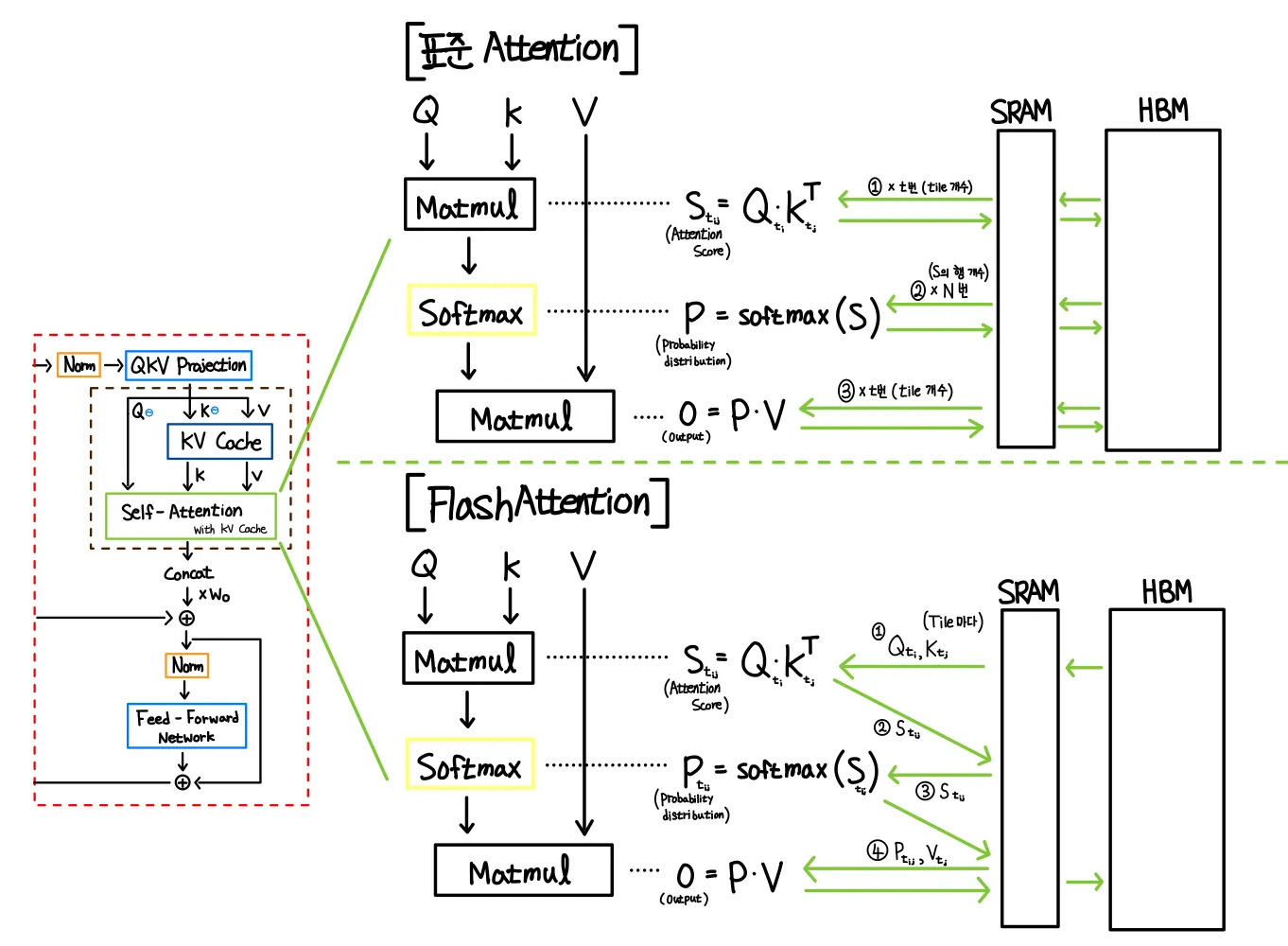
표준 Attention vs FlashAttention 동작 방식 by 필자
2-2. Thread Block 내부: Shared Memory 로드
위에서 Q를 Thread Block(TB)이 각각 Q_t1(TB1)과 Q_t2(TB2)로 나눠서 병렬적으로 처리한다고 설명했다. 그러면 TB1 하나가 어떤 식으로 행렬을 연산하는지 더 자세히 보도록 하자.
Shared Memory에는 Q_t1(128x128)을 로드하고 Inner loop가 끝날 때까지 계속 재사용한다. Inner loop에서 처리할 K와 V는 타일 단위로 스트리밍으로 로드한다.
[TB1 시작]
Q_t1(128×128) → HBM → Shared Memory (한 번만, inner loop 내내 상주)
[inner j=1]
K_t1, V_t1(각 128×128) → Shared Memory (이번 반복에만 사용)
→ 계산 → O 누적
[inner j=2]
K_t2, V_t2 → Shared Memory (이전 버퍼를 덮어씀, double-buffering)
→ 계산 → O 누적
Plain Text
복사
Inner loop에 필요한 K, V 타일들을 한꺼번에 올리지 않는 이유는 Shared Memory 용량 제약 때문이다. d=128, FP16 기준으로 Q_t1은 이고 K와 V 한 쌍은 이다. A100의 통합 L1/Shared Memory(L1 Cache와 Shared Memory는 물리적으로 같은 SRAM을 사용함)는 SM당 192KB이고 Shared Memory는 그중 최대 164KB까지 지정할 수 있다. 따라서 K, V 타일들을 한꺼번에 올리게 되면 Shared Memory가 수용할 수 있는 크기를 넘게 된다.
그래서 재사용하는 Outer loop의 Q는 Shared Memory에 상주시키고 K와 V는 Inner loop에서 갈아 끼우는 구조가 된다. 실제 커널은 다음 K와 V를 미리 당겨 오는(prefetch) cp.async (double-buffering)으로
HBM의 데이터를 로드하는 시간을 최대한 Hiding한다.
2-3. Warp 분할: split-Q
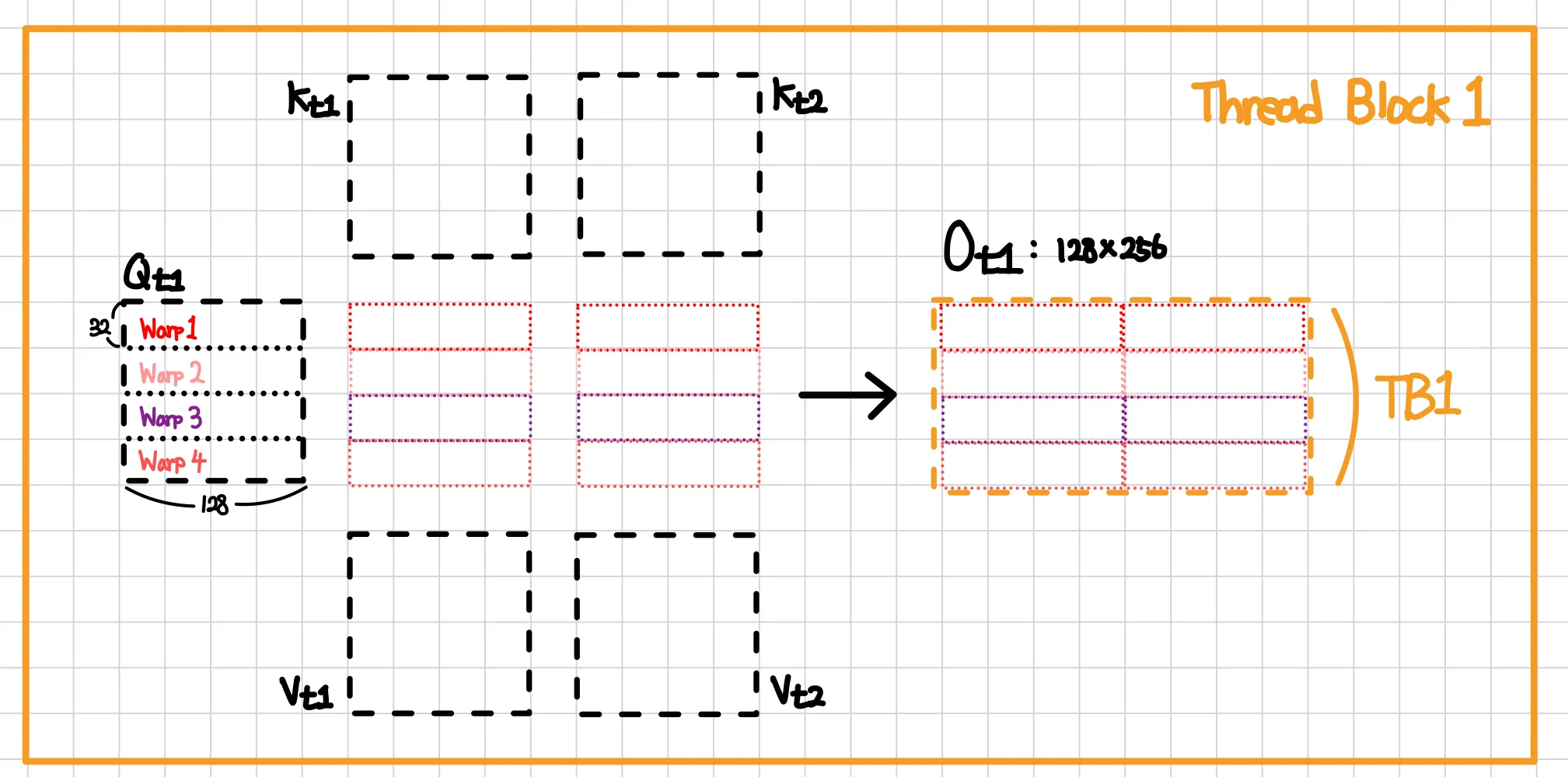
Thread Block 1에서 Warp마다 Q_t1 처리 흐름 by 필자
Q_t1(128x128)은 TB1의 4개 Warp가 32행씩 나눠서 처리한다.
warp | 담당 Q 행 |
Warp 0 | 행 0–31 |
Warp 1 | 행 32–63 |
Warp 2 | 행 64–95 |
Warp 3 | 행 96–127 |
K·V는 4개 warp 전체가 공유한다. 이것이 split-Q이며, 분할 대상은 Q(query 행), 공유 대상은 K·V다.
split-Q에서는 각 warp가 자기 query 행에 대한 완성된 출력을 독립적으로 생성한다. 그래서 warp끼리 각자의 출력을 합칠 필요가 없어 통신 오버헤드가 발생하지 않는다. Register는 Thread별 private 저장공간이라 warp 내부는 통신이 필요 없고, warp 간 통신은 반드시 Shared Memory를 거쳐야 하는데, split-Q는 작업을 warp 경계와 정렬시켜 그 통신 오버헤드를 제거한다.
4개 warp가 각자 을 만들면 세로로 쌓아 O_t1 = 이 된다. 출력이 인 이유는 , 즉 query 행 128과 head dim 128이기 때문이다.
2-4. GPU 내부 구조: SM, SMSP, Register, Shared Memory
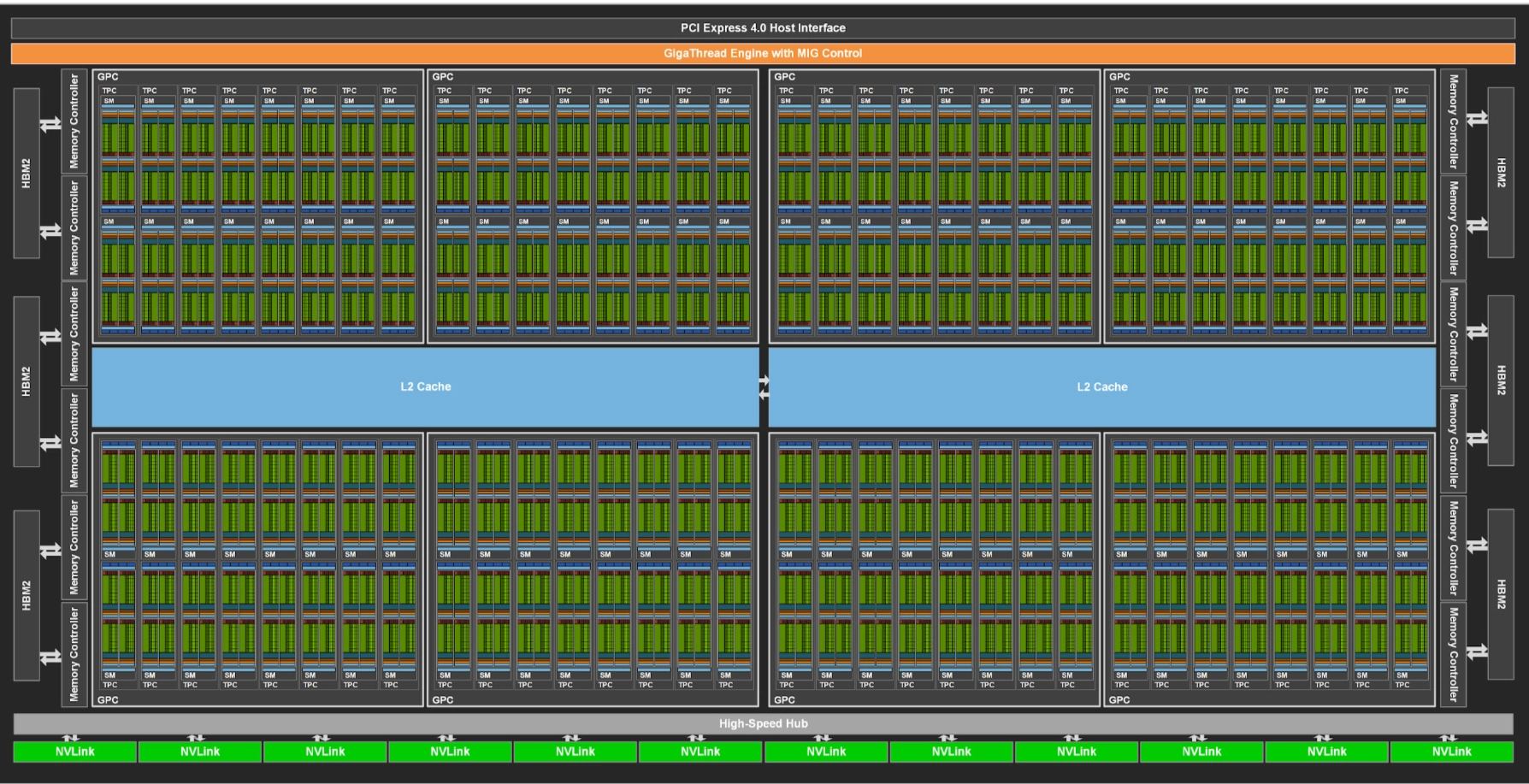
A100 GPU with 128 SMs by NVIDIA A100 Tensor Core GPU Architecture
Warp 내부로 들어가기 전에, 이 구조가 올라타는 하드웨어를 정리한다.
A100의 SM은 4개의 SMSP(SM Sub-Partition)로 나뉜다. 각 SMSP는 거의 독립적으로 동작한다. 다음 표는 SMSP가 물리적으로 갖고 있는 HW들이다:
SMSP가 가진 것 | 개수 |
Warp scheduler | 1개 |
Register file | 16,384개 (32-bit) → SM 전체 65,536개 (256 KB) |
FP32/INT32 cores | 16 FP32 + 16 INT32 |
Tensor Core (3rd gen) | 1개 → SM 전체 4개 |
SMSP의 Register file이 16,384개인 이유
A100 기준, 하나의 SM에 할당된 전체 Register 크기는 256 KB이다. 이 크기를 Byte로 바꾸면, 256 x 1024 = 262,144 Bytes가 된다.
Register file 하나의 크기는 32-bit(= 4 Bytes)이므로, SM 전체에 할당된 Register file 개수는 262,144 / 4 = 65,536개이다. SM은 총 4개의 SMSP로 구성되어 있으니, 각 SMSP당 할당된 Register file 개수는 65,536 / 4 = 16,384개이다.
FlashAttention-2의 4개 warp가 여기서 나온다. SMSP가 4개이므로 warp를 4개 두면 warp 1개당 SMSP 1개로 매핑된다.
Register는 Thread마다 private하게 할당된다. SMSP당 16,384개는 물리적인 한계이며, 거주하는 Thread들이 나누어 가질 수 있다.
Thread가 Register를 많이 쓸수록 동시에 거주할 수 있는 Warp 수가 줄어들어 Occupancy가 떨어진다. Thread당 사용할 수 있는 Register는 최대 255개이며, 이를 넘으면 Register spilling(Local memory, 즉 HBM으로 데이터를 보냄)이 발생해 급격히 느려진다.
Shared Memory와 L1 data cache는 물리적으로 같은 SRAM을 나누어 쓴다. A100은 SM당 통합 192 KB이며, 이 중 Shared Memory로 최대 164 KB까지 지정할 수 있다. Shared Memory는 Thread Block 단위로 할당되고 block 내 모든 warp가 공유하므로, occupancy의 2차 결정자이자 warp 간 통신 통로다.
각 SMSP의 warp scheduler는 거주하는 warp 중 매 사이클마다 실행 가능한 하나를 골라 명령을 발행한다. 어떤 warp가 HBM load(약 400~800 cycles)로 stall되면 즉시 다른 warp로 전환하며, register가 그대로 유지되므로(하나의 warp는 같은 register를 사용함) 전환 비용이 0이다. 이것이 latency hiding의 원리이다.
Part 3. Warp 내부 연산: Tensor Core MMA와 Online Softmax
Warp 1(Q 행 0-31)이 K_t1, K_t2를 순회하며 출력을 만드는 과정을 자세히 보자. Inner loop 한 사이클은 총 세 단계로 구성된다.
K_tj 도착
├─ Step 1: S = Q_t1w1 · K_tjᵀ → Tensor Core (matmul)
├─ Step 2: softmax(S) → CUDA core + __shfl
└─ Step 3: O += P̃ · V_tj → Tensor Core (matmul)
Plain Text
복사
위에서 Step 1과 Step 3만 Tensor Core를 사용한다. Step 2(Softmax)는 Tensor Core가 처리할 수 없는 exp, max, div 연산이라 일반 CUDA Core가 담당한다.
3-1. Tensor Core MMA
S_acc[2][16] = 0 # m 2조각 × n 16조각, 각 16×8 FP32 (register)
for mi in 0..1: # m: 32행 → 16씩 2조각
for ni in 0..15: # n: 128 key → 8씩 16조각
for kk in 0..7: # k: d=128 → 16씩 8번 (누적)
A = Q_t1w1[mi*16 :+16, kk*16 :+16] # 16×16
B = K_t1 [ni*8 :+8, kk*16 :+16]^T # 16×8
S_acc[mi][ni] += mma.sync(A, B) # 16×8 출력 누적
Plain Text
복사
k방향 8번은 같은 S_acc 칸에 누적되어 d 전체를 반영하고, m·n 32칸은 서로 독립적이다.
위의 Step 1에서 가 Tensor Core에서 실행되는 과정을 자세히 보자. (필자는 이 부분을 이해하고자 시간을 꽤 많이 썼다.)
A100의 대표 FP16 MMA는 m16n8k16이다. 한 번의 mma.sync가 처리하는 것은 다음과 같다.
k16이다. 한 번의 mma.sync가 처리하는 것은 다음과 같다.
m16n8k16이 유일한 shape는 아니며 m16n8k8, m8n8k4 등 여러 MMA shape가 존재한다. 하나의 mma.sync는 물리 격자를 여러 번 통과해 완성된다.
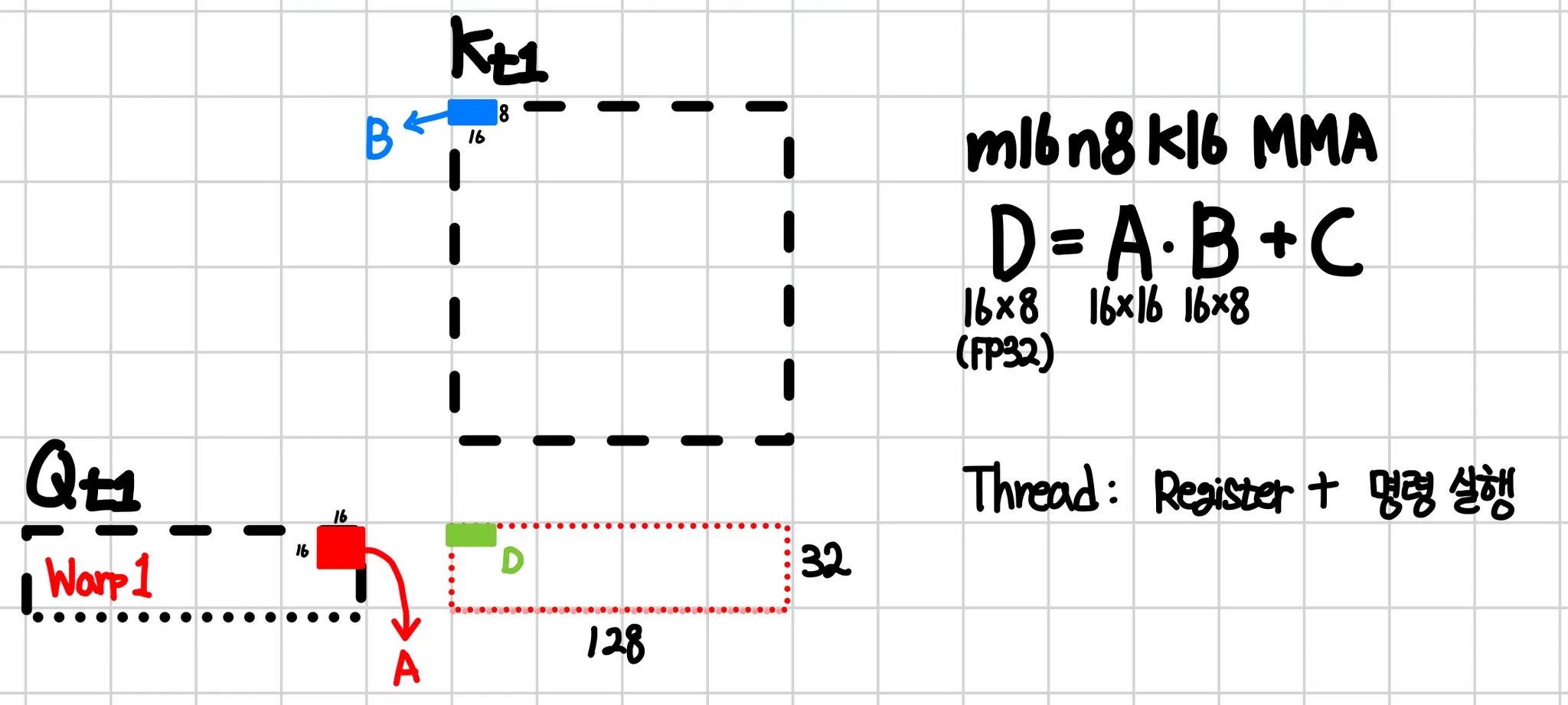
m16n8k16 명령으로 Tensor Core에서 어떻게 연산할지 by 필자
warp가 맡은 ()를 m16n8k16으로 분해한다.
방향 | warp 작업 | MMA 단위 | 분할 |
m (Q 행) | 32 | 16 | 2 |
n (K 행/key) | 128 | 8 | 16 |
k (d, contraction) | 128 | 16 | 8 (누적) |
총 2 × 16 × 8 = 256번의 mma.sync가 발생한다.
Fragment: 32 thread가 행렬을 나눠 갖는 법
Fragment를 이해하기 위해서 먼저 Thread가 무엇인지 정의하자면, Thread는 자기 몫의 Register(물리적 상태)와 Warp Scheduler가 발행하는 명령을 실행할 논리적 단위의 결합이다. 물리적으로 존재하는 것은 Register와 공유 연산 유닛이고, Thread는 이 둘을 묶는 논리 단위이다. 32 Thread가 하나의 명령을 동시에 수행(SIMT; Single Instruction Multi Threads)하는 단위가 Warp이다.
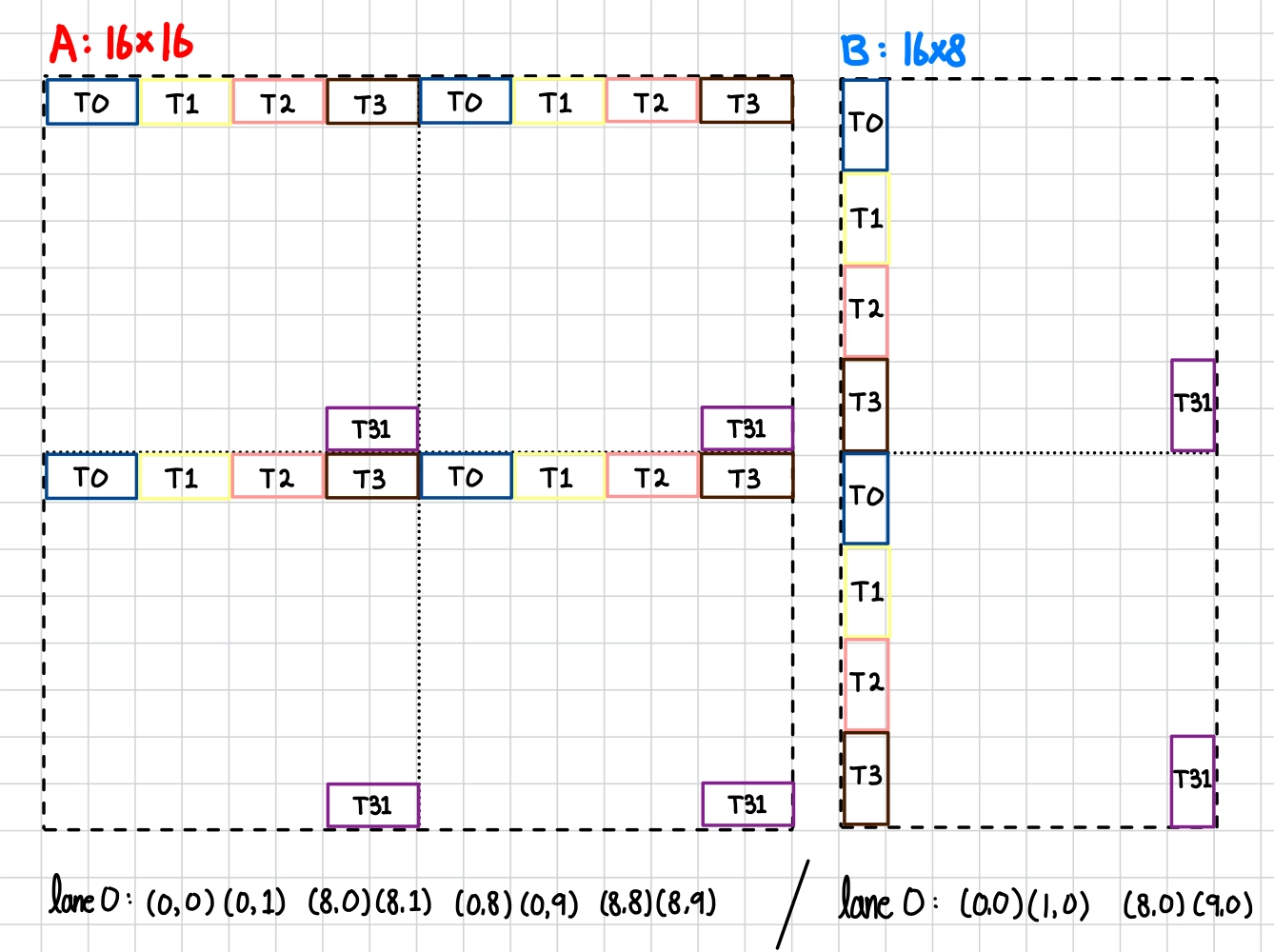
단일 MMA에서 행렬은 32 Thread에 PTX 명세로 고정된 Interleaved 배치로 분산된다.
행렬 | 크기 | thread당 | packing 방향 |
A (Q) | 16×16 = 256 | 8 FP16 | 가로 (같은 행, 연속 열) |
B (Kᵀ) | 16×8 = 128 | 4 FP16 | 세로 (같은 열, 연속 행) |
D (출력) | 16×8 = 128 | 4 FP32 | 가로 |
A의 lane 0 예시는 (0,0)(0,1) / (8,0)(8,1) / (0,8)(0,9) / (8,8)(8,9)로 가로 2개씩 4묶음이다. B의 lane 0 예시는 (0,0)(1,0) / (8,0)(9,0)로 세로 2개씩 2묶음이다.
결과 D의 분배
mma.sync가 끝나면 출력 D(16×8 = 128 FP32)를 32 Thread가 Thread당 4개씩 interleaved하게 나누어 받는다. m16n8k16의 D fragment 배치 규칙은 다음과 같다.
lane 기준:
groupID = lane / 4, threadInGroup = lane % 4
받는 행 = groupID, groupID + 8
받는 열 = threadInGroup*2, threadInGroup*2 + 1
Plain Text
복사
lane | 받는 D 원소 (행,열) |
0 | (0,0)(0,1) (8,0)(8,1) |
1 | (0,2)(0,3) (8,2)(8,3) |
4 | (1,0)(1,1) (9,0)(9,1) |
Systolic MAC 격자: Tensor Core가 빠른 이유
일반 CUDA Core는 곱셈기 1개를 시간축으로 재사용하는 방식이다.
D[i][j] = Σ_k A[i][k]·B[k][j]
→ 곱셈 1개 → 덧셈 1개 → 다음 k → ... (직렬, 수백~수천 사이클)
Plain Text
복사
Tensor Core는 곱셈기와 덧셈기를 하나의 MAC으로 묶고 이를 공간에 펼쳐 격자로 한 번에 연산하는 방식이다.
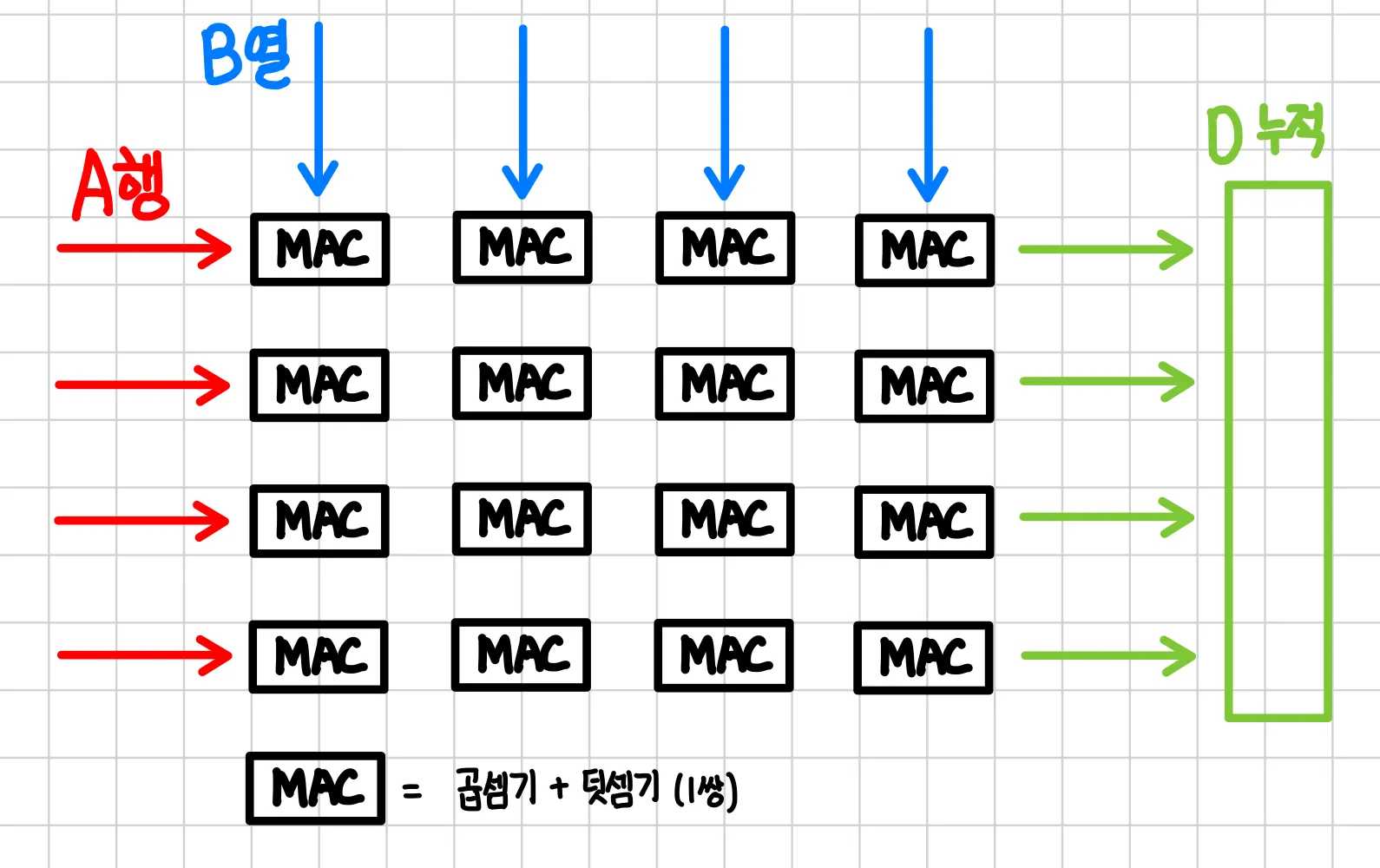
Tensor Core Systolic MAC 격자 구조 by 필자
Tensor Core가 빠른 이유는 다음과 같다:
1.
공간 병렬: 출력 원소마다 전용 MAC 셀이 물리적으로 존재하여 수백 개의 곱셈이 같은 클럭에 동시 수행된다.
2.
누적 융합: 각 셀이 곱셈 후 곧바로 덧셈을 하나의 물리적인 회로에서 처리해 D = A·B + C 의 +C가 추가 비용 없이 함께 이루어진다.
3.
데이터 흐름 재사용: A의 한 행이 격자를 가로지르며 여러 B 열과 만나 한 번 읽은 A를 재사용한다.
3-2. Online Softmax
표준 Softmax는 한 행의 모든 원소를 봐야 max와 분모를 확정할 수 있어 타일링이 불가능하다. Online Softmax는 블록을 순회하며 누적 max(), 누적 분모(), 누적 출력()을 점진적으로 업데이트하고, 새 max가 등장하면 예전 결과를 보정한다.
이해하기 쉬운 예시를 하나 들어보자면:
key | 블록 | S | V |
1 | 블록 1 | 1 | 10 |
2 | 블록 1 | 3 | 20 |
3 | 블록 2 | 5 | 30 |
4 | 블록 2 | 2 | 40 |
표준 softmax로 미리 구한 정답은 전역 max=5, 분모 ℓ=1.2034, 출력 O = 28.986이다.
초기화: m⁽⁰⁾ = −∞, ℓ⁽⁰⁾ = 0, O⁽⁰⁾ = 0.
블록 1 (S=[1,3], V=[10,20]):
m⁽¹⁾ = max(−∞, max(1,3)) = 3
P̃⁽¹⁾ = exp([1,3] − 3) = [0.1353, 1.0]
α₁ = exp(m⁽⁰⁾ − m⁽¹⁾) = exp(−∞) = 0 (초기항 자동 제거)
ℓ⁽¹⁾ = 0·0 + (0.1353 + 1.0) = 1.1353
O⁽¹⁾ = 0·0 + (0.1353·10 + 1.0·20) = 21.353 (정규화 안 됨)
Plain Text
복사
블록 2 (S=[5,2], V=[30,40]) — 보정이 작동하는 지점:
m⁽²⁾ = max(3, max(5,2)) = 5 ← max가 3→5로 갱신
P̃⁽²⁾ = exp([5,2] − 5) = [1.0, 0.0498]
α₂ = exp(m⁽¹⁾ − m⁽²⁾) = exp(3−5) = 0.1353 ← 옛값 down-scale 인수
ℓ⁽²⁾ = 0.1353·1.1353 + (1.0 + 0.0498) = 1.2034 (표준 분모와 일치)
O⁽²⁾ = 0.1353·21.353 + (1.0·30 + 0.0498·40)
= 2.889 + 31.992 = 34.881 (정규화 안 됨)
Plain Text
복사
마지막에 한 번만 정규화:
O = O⁽²⁾ / ℓ⁽²⁾ = 34.881 / 1.2034 = 28.986 (정답과 일치)
Plain Text
복사
α₂ = exp(m⁽¹⁾ − m⁽²⁾)는 옛 max 기준을 새 max 기준으로 환산하는 인수다. 매 블록마다 ÷ℓ을 하지 않고도 마지막 한 번의 나눗셈으로 정확한 결과가 나온다.
A100 기준 matmul은 non-matmul보다 16배 빠른데, FlashAttention-2는 정규화를 루프 종료 후 한 번만 수행하여 non-matmul FLOPs를 줄인다.
“50대의 추교현이 20대의 추교현에게 감사할 수 있도록 하루하루 최선을 다해 살고 있습니다.”
The End.