

현재(26년 5월 기준) 필자는 대학원 컴퓨터공학과 석사과정 3차 학기이며, “온-디바이스 환경에서 LLM을 추론시킬 때 메모리를 최대한 적게 쓰면서 성능이 유지되는 방향”으로 연구 아이디어를 찾아가는 중이다. 구체적으로는 KV Cache를 양자화(압축)하는 쪽으로 연구 방향을 잡았으며, 이 글은 Weight(가중치) 양자화 방법 중 뿌리에 가까운 GPTQ를 제대로 이해하고자 약 1주일에 걸쳐서 읽고 정리한 글이다.
1. Introduction
GPT-3-175B는 FP16 기준으로 파라미터만 326GB를 차지한다. 이런 거대 모델을 단일 GPU에서 돌릴 수 있게 만드는 핵심 기술이 양자화(Quantization)다.
이 글에서는 ICLR 2023에 발표된 GPTQ 논문을 정리한다. GPTQ는 175B 파라미터 모델을 단일 NVIDIA A100 GPU에서 약 4시간 만에 3~4비트로 양자화하면서, FP16 baseline 대비 거의 무시할 수 있는 정확도 손실만 발생시킨다.
GPTQ를 이해하려면 그 전신인 OBQ(Optimal Brain Quantization)를 먼저 알아야 한다. GPTQ는 OBQ의 핵심 아이디어를 유지하면서 세 가지 결정적인 개선을 통해 대규모 모델 양자화를 가능하게 만든 알고리즘이기 때문이다.
2. Background
2.1 Transformer Block 구조
이 논문에서는 어떠한 단위로 양자화를 하는지 이해하기 위해서 Transformer Block 구조를 간단히 설명하고자 한다. GPT-3-175B 기준으로 96개의 Transformer Block이 쌓여 있고, 각 block은 다음 6개의 weight 행렬(layer)로 구성된다.
Transformer Block (96개)
├─ Self-Attention
│ ├─ W_Q (Query Weight)
│ ├─ W_K (Key Weight)
│ ├─ W_V (Value Weight)
│ └─ W_O (Output Weight)
└─ FFN
├─ W_FC1 (Up Weight)
└─ W_FC2 (Down Weight)
Plain Text
복사
GPTQ 논문에서는 각 weight 행렬 하나를 “layer”라고 부른다. 한 layer는 하나의 행렬곱 연산에 해당하는 단위다. 따라서 GPT-3-175B 전체에는 총 576개(96 6)의 layer가 있고, GPTQ는 이 layer들을 하나씩 독립적으로 양자화한다.
2.2 Layer-wise Quantization
한 linear layer의 weight 는 크기의 행렬이다.
GPT-3 기준 이므로:
•
Attention의 : 모두
•
FFN의 : (up projection, 4배 차원 확장)
•
FFN의 : (down projection, 4배 차원 감소)
입력 는 (: calibration 데이터의 총 토큰 수)
Layer의 forward pass:
2.3 Calibration 데이터
Post-Training Quantization(PTQ)은 재학습 없이 양자화를 수행하므로, 모델이 실제 입력을 어떻게 처리하는지 알 수 있는 유일한 방법은 소량의 대표 데이터를 forward pass하여 각 layer의 입력 활성값을 관찰하는 것이다. 이를 Calibration(캘리브레이션)이라 한다.
GPTQ에서는 다음과 같이 Calibration을 수행한다:
•
데이터셋: C4 (웹 크롤링 generic text)
•
샘플 수: 128개 segment
•
각 segment 길이: 2048 tokens
2.3.1 가 만들어지는 방식
128개 segment를 모델의 각 layer마다 forward pass하고, 특정 layer 위치에서 받는 activation을 수집한다.
Segment 1 (2048 tokens) → 모델 통과 → layer ℓ에서 activation X_1 (d_col × 2048)
Segment 2 (2048 tokens) → 모델 통과 → layer ℓ에서 activation X_2 (d_col × 2048)
...
Segment 128 → ... → X_128 (d_col × 2048)
Plain Text
복사
각 layer에서 수집된 128개의 activation ()를 가로로 concatenate하면, 가 만들어진다.
()
즉, 는 128개가 아니라, 128개를 모두 합친 하나의 큰 행렬이라고 보면 된다.
2.3.2 실제 알고리즘 흐름
1. Calibration: 128 segments를 모델에 통과시켜 각 layer의 X 수집 (한 번)
2. 각 layer마다:
a. H = 2XX^⊤ 계산 (한 번)
b. H^{-1} 계산 (한 번)
c. OBQ/GPTQ 알고리즘 실행 (한 번)
3. 다음 layer로 이동
Plain Text
복사
Calibration의 128개 segments가 각 layer마다 통과되어 를 만들고 이 를 가지고 Hessian을 계산하는 데 사용한다.
또한, 특정 Layer의 는 앞 layer를 통과한 activation으로 사용한다. 이 방식으로 양자화 오차가 누적된 실제 환경에서의 입력처럼 다음 layer를 보정하여 정확도가 향상되는 효과를 갖는다.
2.4 Hessian Matrix (헤세 행렬) 설명
2.4.1 Hessian 일반적인 정의
한마디로 정의하면, 함수의 2차 미분이다. 1차 미분인 Gradient는 “함수값이 얼마나 변하는가(= 함수값의 변화량)”이라면, 2차 미분인 Hessian은 “그 기울기가 어떻게 변하는가(= 함수값의 변화량의 변화량 = 기울기의 변화량 = 함수의 곡률)”이다.
예를 들면, 1차원 함수 가 있다고 가정하자.
•
: 1차 미분 (Gradient) - 가 변함에 따라, 함수값이 얼마나 변하는가
•
: 2차 미분 (Hessian) - 가 변함에 따라, 함수값의 변화가 얼마나 변하는가
여기서 함수값의 변화가 얼마나 변하는가를 “곡률” 또는 “가파른 정도” 또는 “기울기의 민감도”라고도 표현할 수 있다.
 Hessian을 어떻게든 이해하고자 했던 흔적.jpg
Hessian을 어떻게든 이해하고자 했던 흔적.jpg2.4.2 양자화 맥락에서의 Hessian Matrix
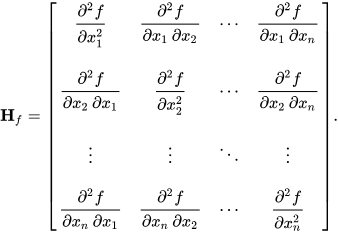
Fig 1. Definiton of Hessian Matrix
Hessian Matrix는 함수가 만약 처럼 변수가 여러 개인 다변수 함수일 때, 모든 변수 조합에 대한 2차 편미분 값을 모아 놓은 정방 행렬(Square Matrix)이다.
양자화 맥락에서는 수많은 가중치 값()들이 변수가 된다. 이때 Hessian Matrix는 두 가지 중요한 정보를 담고 있다.
1.
대각 원소 (Base Sensitivity): 가중치 ‘단독’의 곡률. 을 양자화했을 때, 어떠한 다른 가중치들을 조정하지 않았을 때 발생하는 양자화 오차에 기여 정도
2.
비대각 원소 (Interaction): 가중치 과 의 ‘상호작용’ 계수. 을 양자화했을 때, 양자화 오차를 줄이기 위해서 나머지 가중치()를 얼만큼 조정시킬지의 정도
2.4.3 양자화 목적 함수 ()
양자화 단위인 각 layer에서의 양자화 목표는 원래 출력값과 양자화된 출력값의 차이를 최소화하는 것이다.
•
: 원본 weight (한 행렬의 row 벡터)
•
: 양자화된 weight (찾을 것)
•
: 이 layer의 입력 (calibration 데이터로부터 얻음)
목적 함수 를 최소화하는 것이 양자화의 목표이고, 미분하려는 독립 변수는 가중치의 차이인 이다.
을 에 대해서 두 번 미분하면 이 나오게 되는데, 자세한 유도 과정은 아래 토글에 정리해 두었다.
유도 과정
목적 함수 은 가중치의 차이인 에 대한 2차 함수이다. 이를 두 번 미분하면 만 남는다. 즉, “가중치 오차()가 얼마든 상관없이, 오직 입력 데이터 의 분포에 의해서만 양자화 오차가 얼마나 가파르게 바뀌는지가 결정된다”는 것을 보여준다.
2.4.4 Hessian 역행렬
위에서 설명한 Hessian 은 “weight를 흔들면 양자화 오차가 얼마나 가파르게 변하는가”를 정량화한 값이다.
양자화해서 풀어야 하는 입장에서는 반대 방향으로 접근해야 된다.
Q. weight 를 양자화해서 오차가 발생했는데, 이 오차를 줄이려면 다른 weight들을 어떻게 움직여야 하는가?
이 반대 방향의 질문에 답하려면 Hessian의 역행렬 (역헤시안)이 필요하다.
역행렬을 왜 하는가?
식에서 를 찾기 위해서는 “2를 곱한다”의 반대 연산인 “을 곱한다”가 필요하다.
행렬에서도 같은 논리이다. 정사각 행렬 의 역행렬 는 다음을 만족하는 행렬이다:
따라서, 특정 weight의 양자화로 인해 발생한 오차를 줄이기 위해서 다른 weight들을 어떻게 보정해야 할지를 알기 위해서 이 필요하다.
(base sensitivity)가 “다른 weight 보정 없이 weight 가 양자화 오차에 미치는 직접적인 영향력(기여도)”이라면, (effective sensitivity의 역수)는 “다른 weight들이 최적으로 보정해줄 수 있는 효과까지 모두 고려한 민감도의 역수”다.
2.5 Optimal Brain Quantization (OBQ)
GPTQ는 기존 가중치 양자화 방식인 OBQ를 개선한 알고리즘이다. 따라서, GPTQ를 이해하기 위해서는 OBQ가 어떻게 동작하는지 알아야 한다.
OBQ는 한 row의 weight들을 하나씩 양자화하면서 발생하는 오차를 Hessian으로 다른 weight들을 미세 조정하여 상쇄시키는 알고리즘이다.
2.5.1 기존 기법 대비 OBQ 장점
RTN (Round-to-Nearest): 가장 단순함. 모든 weight를 가장 가까운 grid 값으로 반올림하는 방식. 매우 빠르지만 weight 간 상호작용을 무시하므로 4비트 이하에서 정확도 급락함
AdaRound (Nagel et al., 2020): RTN은 단순히 가까운 쪽을 선택했다면, AdaRound는 데이터를 보고 더 나은 방향 쪽으로 round를 한다. 이를 위해서 학습이 필요하여 RTN보다는 정확하지만 큰 모델에서는 비싸짐. (Weight 간 상호작용은 고려하지 않음)
OBQ는 Weight 간 상호작용을 Second-order 정보(Hessian)로 활용하여 양자화 오차를 줄여 성능을 최대한 유지하는 방식이다.
2.5.2 양자화 Datatype과 Scaling 전략
OBQ/GPTQ가 어떤 형태로 양자화하는지 알아보자.
•
Datatype: INT3 또는 INT4를 사용함
•
Asymmetric quantization: zero point + scale (single FP16 값으로 grid 정의)
◦
(scaling factor): 양자화 grid의 한 칸 폭
◦
(zero point): 양자화 grid의 시작점
•
Per-row quantization: OBQ/GPTQ는 각 row마다 별도의 scale + zero point를 사용함 (원문: “standard uniform per-row asymmetric quantization on the min-max grid”)
OBQ 알고리즘 전에 Scale이 결정된다. 즉, Grid 자체는 알고리즘 시작 전에 결정되어 고정된다. 이 부분이 OBQ의 한계점이 된다.
원문: “we assume that the quantization grid for is fixed before the process”
2.5.3 Setup
간단한 예시와 함께 설명해 보자면, 한 row에 weight 3개:
입력 :
하나의 row :
계산된 Hessian:
Hessian 역행렬(역헤시안):
양자화 grid는 정수 이며, 는 아직 양자화되지 않은 weight 인덱스 집합이다. (초기 )
2.5.4 Step A: Greedy로 양자화 비용이 작은 weight 선택
각 weight에 대해 비용을 계산하고, 가장 작은 비용의 weight를 선택한다.
Cost 작은 가중치 구하는 식:
weight | 값 | quant 결과 | quant error | 비용 (cost) | |
0.6 | 1 | 0.0938 | |||
1.4 | 1 | 0.3750 | |||
-0.3 | 0 | 0.1771 |
비용이 가장 작은 를 선택한다.
위 식의 분자는 단순한 rounding error의 제곱이고, 분모는 effective sensitivity의 역수다. 분자/분모를 통해 rounding error가 실제 출력 오차로 얼마나 전환되는가의 진짜 비용을 계산한다. OBQ 이전 baseline인 RTN은 분모를 고려하지 않고 모든 weight를 단순히 round한다. OBQ의 차별점은 second-order 정보로 weight 간 상호작용을 정밀하게 다룬다는 것이다.
⇒ 시간복잡도:
2.5.5 Step B: 양자화 및 나머지 weight 보정
선택한 를 grid 값으로 round하면 출력에 오차가 발행한다. 이를 상쇄하기 위해 의 나머지 weight들을 미세 조정한다.
나머지 weight 보정 ( 제외):
•
•
⇒ 시간복잡도:
2.5.6 Step C: Hessian 역행렬 업데이트
가 양자화되어 더 이상 보정할 수 없기에, 다음 iteration을 위해 에서 의 행과 열을 제거해야 한다.
위의 식을 통해 기존 Hessian 역행렬에서 의 행과 열의 영향을 확실히 제거하여, 남은 weight들에 대한 새로운 (작아진) 역행렬을 만든다. 처음부터 역행렬을 다시 계산()하지 않고 외적과 뺄셈만으로() 처리한다.
⇒ 시간복잡도: - 외적이 행렬을 만들므로 가장 비싼 연산
2.5.7 OBQ의 시간복잡도
한 row를 처리:
•
Step A, B, C를 번 반복
•
가장 비싼 Step C가 이므로 한 row당
전체 weight 행렬(개 row 독립적으로 처리) 처리:
⇒ 최종 시간복잡도:
3. Method
3.1 GPTQ의 세 가지 핵심 개선사항
GPTQ는 OBQ의 세 가지 한계를 각각 해결한다.
문제 | 원인 | GPTQ의 해법 |
너무 느림 | 복잡도 | Step 1: Arbitrary Order |
GPU 활용도 낮음 | 메모리 대역폭 병목 | Step 2: Lazy Batch-Updates |
수치적 불안정 | 반복 업데이트의 부동소수점 오차 누적 | Step 3: Cholesky Reformulation |
3.2 Step 1: Arbitrary Order Insight
3.2.1 핵심 관찰
OBQ가 매번 Greedy하게 Cost가 낮은 weight를 선택했는데, GPTQ 저자들은 “대규모 모델에서는 Greedy 순서와 고정된 순서의 성능 차이가 거의 없다”는 사실을 발견했다.
원문: “Interestingly, we find that, while this quite natural strategy does indeed seem to perform very well, its improvement over quantizing the weights in arbitrary order is generally small, in particular on large, heavily-parametrized layers.”
3.2.2 시간복잡도가 감소하는 이유
OBQ는 row마다 다른 양자화 순서를 따른다. 그래서 각 row마다 독립적으로 Hessian 역행렬을 관리하고 업데이트해야 한다.
[OBQ의 Example]
Row 1의 양자화 순서: col 4 → col 1 → col 3 → col 2
Row 2의 양자화 순서: col 2 → col 4 → col 1 → col 3
Row 3의 양자화 순서: col 1 → col 3 → col 4 → col 2
…
애초에 Hessian은 이므로 입력 에만 의존하지 weight에는 의존하지 않으므로, 모든 row가 수학적으로 같은 Hessian을 갖는다. GPTQ는 모든 row를 같은 column 순서로 양자화한다. 그러므로 Hessian 역행렬 업데이트가 row마다 아니라 column마다 한 번만 일어난다.
[GPTQ의 Example]
Row 1의 양자화 순서: col 1 → col 2 → col 3 → col 4
Row 2의 양자화 순서: col 1 → col 2 → col 3 → col 4
Row 3의 양자화 순서: col 1 → col 2 → col 3 → col 4
…
3.2.3 GPTQ의 시간복잡도 계산
•
Step A. col 선택 -
•
Step B. col 양자화 및 나머지 col 보정 -
◦
여기서 나머지 col은 모든 row의 col ~ 임
•
Step C. 업데이트 -
→ Column 하나당 비용: +
→ Column 개 비용: x [ + ] = +
⇒ 전체 시간복잡도:
3.3 Step 2: Lazy Batch-Updates
3.3.1 문제 인식
Step 1로 이론적인 시간 복잡도는 줄었지만 실제 GPU에서는 여전히 느리다. 그 이유는 메모리 대역폭 병목 때문이다.
GPTQ는 column을 하나씩 처리하면서 매번 두 종류의 큰 영역을 업데이트한다:
1.
Weight 행렬 (모든 row 남은 columns)의 양자화되지 않은 영역: 현재 양자화한 column의 양자화 오차를 흡수하기 위한 보정
2.
Hessian 역행렬 (): 현재 양자화한 row/column 제거를 위한 업데이트
매 column마다 이런 거대한 행렬을 GPU 메모리에서 읽고, 외적과 뺄셈 같은 가벼운 연산만 수행한 뒤, 다시 메모리에 쓰기를 반복한다. 이는 GPU의 강력한 연산 능력 대비 메모리 대역폭이 부족하여 GPU 활용도가 낮아 전체 속도가 저하되는 문제가 발생한다.
3.3.2 핵심 관찰
Column 의 양자화 결정은 column 자체에만 영향을 주기 때문에 미래 column들( 이후)의 업데이트는 바로 반영하지 않아도 된다.
원문: “Such operations cannot properly utilize the massive compute capabilities of modern GPUs, and will be bottlenecked by the significantly lower memory bandwidth.”, “The final rounding decisions for column are only affected by updates performed on this very column, and so updates to later columns are irrelevant at this point in the process.”
3.3.3 전체적인 흐름

Algorithm 1. GPTQ pseudo code
1.
Weight 행렬을 단위 블록으로 나눔
•
Block 1: columns 1~128
•
Block 2: columns 129~256
•
…
2.
한 블록 내부: column 하나씩 양자화하면서, 그 블록 내부의 weight들만 즉시 업데이트
3.
블록 전체가 끝나면, 누적된 오차 를 한 번에 곱해서 블록 외부의 모든 나머지 weight를 batch로 한꺼번에 업데이트
비유하자면, 도서관에서 책 한 권 정리할 때마다 카탈로그(모든 자료의 정보를 체계적으로 등록한 목록) 전체를 들고 와서 업데이트하는 대신, 한 책장(블록) 분량을 다 정리한 후 그 책장 정보만 모아서 카탈로그에 한 번 반영하는 방식이다.
3.3.4 구체적인 예시
Weight의 한 row:
블록 크기
블록 분할: , …
Block 1 처리 (i = 0)
•
Col 1:
1.
col 1 양자화: Q[:, 1] ← quant(W[:, 1])
2.
반올림 오차 저장: E[:, 0] ← W[:, 1] - Q[:, 1] (E의 0번째 위치)
3.
블록 내부 weight들 보정: W[:, 1:2] ← W[:, 1:2] - E[:, 0] · H^{-1}[1, 1:2]
•
Col 2:
1.
col 2 양자화: Q[:, 2] ← quant(W[:, 2])
2.
반올림 오차 저장: E[:, 1] ← W[:, 2] - Q[:, 2] (E의 1번째 위치)
3.
블록 내부 weight들 보정: W[:, 2:2] ← (빈 범위)
•
행렬 상태: E = [E[:, 0], E[:, 1]] = [(col 1의 rounding error), (col 2의 rounding error)]
•
Block 1 종료 후 Batch(양자화 안 된 전체) 보정:
W[:, i+B:] ← W[:, i+B:] - E · H^{-1}[i:i+B, i+B:]
W[:, 2:] ← W[:, 2:] - E · H^{-1}[0:2, 2:]
Plain Text
복사
•
행렬곱 :
⇒
위의 행렬곱 결과처럼 col 3~8에 대한 보정을 한꺼번에 적용한다.
Block 1 종료 후, Block 2, 3… 처리
3.4 Step 3: Cholesky Reformulation
3.4.1 문제 인식
큰 모델에서 업데이트를 수천 번 반복하면 부동소수점 오차가 누적되어 이 indefinite 상태되고 이로 인해 알고리즘이 잘못된 방향으로 weight를 이상하게 업데이트하여 양자화 결과를 망가뜨린다.
원문: “Specifically, it can occur that the matrix becomes indefinite, which we notice can cause the algorithm to aggressively update the remaining weights in incorrect directions.”
선형대수학 기본 지식
Indefinite 상태
대칭 행렬의 고유값이 양수와 음수가 섞인 상태
분류 | 고윳값 | 직관 |
Positive definite (양정치) | 모두 양수 | 그릇 모양 (위로 볼록) |
Positive semi-definite (양반정치) | 0 이상 | 그릇 모양 + 평평한 방향 |
Negative definite (음정치) | 모두 음수 | 거꾸로 된 그릇 |
Indefinite | 양수와 음수 섞임 | 안장 모양 |
고유벡터 (eigenvector) & 고윳값 (eigenvalue)
어떤 벡터()에 선형변환()을 시켰을 때, 벡터()와 방향은 같지만 크기()만 변한다면 그 벡터()를 고유벡터(eigenvector)라고 하며, 크기인 를 고윳값이라고 한다.
대칭 양정치 행렬 (Symmetric Positive Definite, SPD)
고윳값이 양수인 Symmetric(대칭 행렬)을 의미한다. 대표적인 예시가 이다.
문제의 메커니즘은 다음과 같다:
1.
업데이트는 외적과 뺄셈을 포함한다.
2.
각 연산에서 부동소수점 오차가 미세하게 발생한다.
3.
매 업데이트가 이전 업데이트 결과에 의존하므로 오차가 계속해서 누적된다.
4.
일부 대각 원소가 양수에서 작은 음수로 넘어가서 indefinite 상태가 될 수 있다.
Indefinite 상태가 문제되는 이유:
와 가 대칭 양정치 행렬인 이유
가 대칭 행렬일까?
대칭 행렬은 Transpose해도 자기 자신이다.
따라서, 는 대칭 행렬이다.
가 양정치 행렬일까?
또한, H가 양정치인지 아닌지를 형태가 항상 0보다 큰지 아닌지로 증명할 수 있다.
임의의 0이 아닌 벡터 에 대해:
따라서, 는 대칭이자 양정치 행렬이다.
도 대칭 양정치 행렬이다.
그렇다면, 의 역행렬인 도 대칭이자 양정치 행렬이라는 것을 알 수 있다.
•
대칭성 보존:
•
양정치성 보존: 가 양정치 → 의 모든 고윳값이 양수 → 의 고윳값은 로 모두 양수 → 양정치
은 대칭 양정치 행렬인데, Indefinite 상태가 되면 고윳값에 음수도 섞이게 된다. 그렇게 되면 가 양수에서 음수로 넘어가면 보정 공식의 부호가 뒤집힌다. 오차를 줄이려고 한 보정이 오히려 오차를 증폭시키는 방향으로 작용하여 양자화 결과가 완전히 망가질 수 있다.
3.4.2 핵심 관찰
GPTQ 저자들은 OBQ의 row 제거 연산이 사실 Cholesky decomposition의 한 스텝과 거의 같다는 것을 발견했다. Cholesky decomposition은 대칭 양정치 행렬 로 분해하는 표준 기법이며, 수치적으로 매우 안정적인 알고리즘이다.
그러면 다음 아이디어를 도출할 수 있게 된다:
의 모든 row 정보를 처음에 한 번 Cholesky decomposition으로 미리 계산해 두자. 그리고 미리 계산한 값을 매 column 처리마다 해당되는 row 일부분을 읽어오고 따로 업데이트하지 않는다.
즉, 는 대칭 양정치 행렬이기 때문에 을 Cholesky decomposition해서 으로 표현할 수 있다.
3.4.3 Cholesky decomposition
Cholesky decomposition: 대칭 양정치 행렬 를 로 분해 (은 하삼각행렬)
을 Cholesky decomposition:
위의 분해는 정보 손실 없이 을 로 표현한 것이다. 이후 매 column 처리마다 에서 정보를 읽어온다. 의 번째 row 한 줄을 읽으면 column 처리에 필요한 모든 정보를 얻을 수 있다. 자체는 절대 수정하지 않으므로 부동소수점 오차 누적이 없다.
3.5 GPTQ 전체 흐름 정리
세 Step이 누적되어 175B 모델 양자화를 가능하게 한다:
OBQ (작은 모델용)
복잡도: O(d_row × d_col³)
한계: 너무 느림, GPU 비효율, 수치 불안정
↓ Step 1: Arbitrary Order
모든 row가 같은 column 순서 → Hessian 공유
복잡도: O(d_row × d_col² + d_col³)
가속: O(min{d_row, d_col})배 ≈ 수천 배
↓ Step 2: Lazy Batch-Updates
128 columns 단위 블록, 즉시 업데이트 → batch 업데이트
가속: 약 10배 추가 (메모리 대역폭 병목 해소)
↓ Step 3: Cholesky Reformulation
H^{-1} 매번 수정 → Cholesky 분해 후 읽기만
효과: 수치 안정성 + 추가 속도
↓
GPTQ
175B 모델을 단일 A100 GPU에서 4시간에 양자화
Plain Text
복사
GPTQ의 세 Step 중 하나라도 빠지면 안 됨:
•
Step 1 X : 너무 느려서 실제 사용 불가
•
Step 2 X : 이론은 빠르지만 실제 GPU에서 메모리 병목
•
Step 3 X : 큰 모델에서 오차가 누적되어 결과 망가짐
4. Evaluation
4.1 Perplexity 비교 (OPT 모델 패밀리, WikiText2)
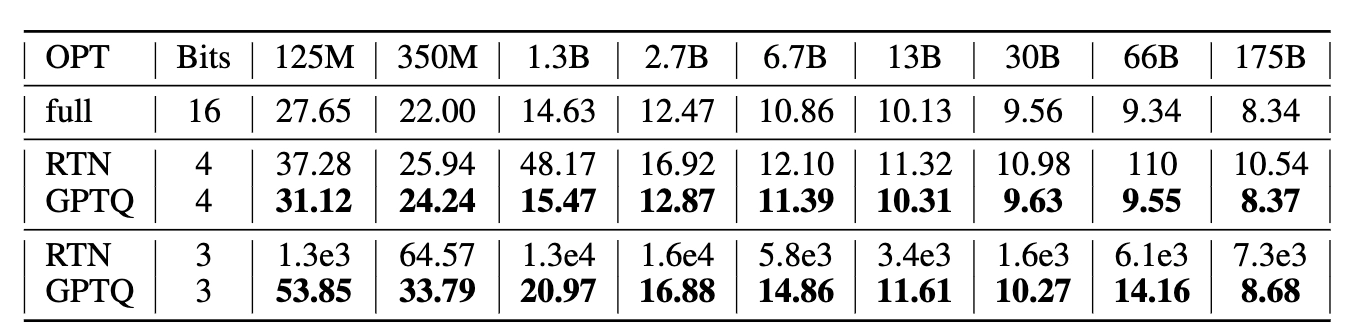
Table 1. OPT perplexity results on WikiText2
GPTQ 4bit는 FP16 baseline 대비 거의 손실이 없다(175B에서 0.03 차이). RTN은 3bit에서 완전히 붕괴하지만 GPTQ는 RTN 대비 성능을 유지한다.
4.2 추론 성능 비교

Table 2. Average per-token latency (batch size 1) when generating sequences of length 128
3-bit 양자화된 OPT-175B를 단일 A100에서 실행하면 FP16 대비 3.25배 빠르다. 메모리 이동 비용이 줄어든 결과로 볼 수 있다.
또한, A6000 GPU로 FP16 모델을 돌리기 위해서는 8대의 GPU가 필요했지만, GPTQ를 통해 단 2대만으로도 구동이 가능해졌고 A100 GPU 5대가 필요했는데 단 1대(Single GPU)만으로 175B급 모델을 실행할 수 있게 되었다.
5. Conclusion
GPTQ 논문에서 명시한 한계점은 다음과 같다:
•
Mixed-precision에 대한 하드웨어 지원 부재로 실제 행렬 곱셈 자체에 대한 speedup은 없다.
•
Activation 양자화는 다루지 않는다.
•
작은 모델에서는 OBQ 대비 정확도 차이가 더 크게 나타날 수 있다.
또한 본질적인 한계로는 Grid가 고정된 상태에서의 rounding 최적화만 한다는 점이다. 후속 연구(AWQ의 Activation-aware scaling 등)에서는 grid 최적화와 rounding 최적화를 동시에 다루고 있다.
GPTQ는 이후 AWQ, SmoothQuant, KIVI 등 LLM 양자화 연구의 표준 baseline이 되었다. 핵심 인사이트인 “second-order 정보(Hessian)를 활용한 후처리 보정”은 KV cache 양자화 등 후속 연구에서도 직간접적으로 영향을 미치고 있다.
“50대의 추교현이 20대의 추교현에게 감사할 수 있도록 하루하루 최선을 다해 살고 있습니다.”
The End.