

1. KV Cache란 무엇인가
KV Cache를 이해하려면, 먼저 Transformer의 Self-Attention 연산을 이해해야 한다.
Transformer에서 각 토큰은 세 가지 벡터로 변환된다: Query(Q), Key(K), Value(V). Attention 연산은 Q와 K의 내적으로 각 토큰 간의 관련도(attention score)를 계산하고, 이 score로 V를 가중합하여 최종 출력을 만든다. 수식으로 표현하면 다음과 같다:
LLM은 토큰을 하나씩 순차적으로 생성하는데, 이를 autoregressive하게 생성한다고 한다. 새로운 토큰을 생성할 때마다 이전에 생성된 모든 토큰의 K와 V가 다시 필요하다. 예를 들어, 100번째 토큰을 생성하려면 1~99번째 토큰 전부의 K, V와 attention 연산을 수행해야 한다.

Q. 왜 새로운 토큰을 생성할 때마다 이전에 생성된 모든 토큰의 K와 V가 다시 필요할까?
“이전에 생성된 일부 토큰만 참고하면 안 되나?”라고 생각할 수 있지만, 문제는 어떤 토큰이 중요한지를 알기 위해서는 모든 토큰과 비교를 끝내야 한다는 점이다.
예를 들어 “나는 3년 전에 파리에서 먹었던 크루아상이 그립다. 그래서 오늘은 “이라는 문장에서 다음 토큰을 생성한다고 하자. “빵집”이라는 토큰을 생성하려면 앞쪽에 있는 “파리”, “크루아상” 같은 토큰이 핵심이다. 바로 직전의 “오늘은”만으로는 맥락을 파악할 수가 없다.
어떤 토큰이 중요한지는 문장의 의미에 따라 매번 달라진다. 때로는 바로 직전 토큰이, 때로는 수천 토큰 전의 토큰이 결정적일 수 있다. 이것을 사전에 알 수 없기 때문에, Attention은 원칙적으로 모든 이전 토큰의 K와 score를 계산하고, 모든 이전 토큰의 V를 가중합에 포함시켜야 한다.
여기서 핵심은 이전 토큰들의 K와 V는 한 번 계산되면 값이 변하지 않는다는 것이다. 1번째 토큰의 K와 V는 2번째 토큰을 생성할 때나 100번째 토큰을 생성할 때나 동일하다. 그렇다면 매번 다시 계산하는 것은 엄청난 낭비인 것이다.
Q. 왜 이전 토큰의 K, V는 한 번 계산되면 변하지 않을까?
K와 V가 어떻게 만들어지는지를 보면 알 수 있다. 각 토큰의 K와 V는 다음과 같이 계산된다:
여기서 는 번째 토큰의 임베딩이고, 는 학습된 가중치 행렬이다. 는 번째 토큰 자체의 표현이므로 바뀌지 않으며, 도 학습이 끝난 고정된 파라미터이므로 변하지 않는다.
KV Cache는 바로 이 이전 토큰들의 K, V 벡터를 GPU 메모리에 저장해 두고 재사용하는 기법이다. 새로운 토큰을 생성할 때는 해당 토큰의 Q, K, V만 새로 계산하고, 이전 토큰들의 K, V는 캐시에서 가져와 attention 연산에 사용한다.
2. 그렇다면, KV Cache가 없다면 어떻게 될까
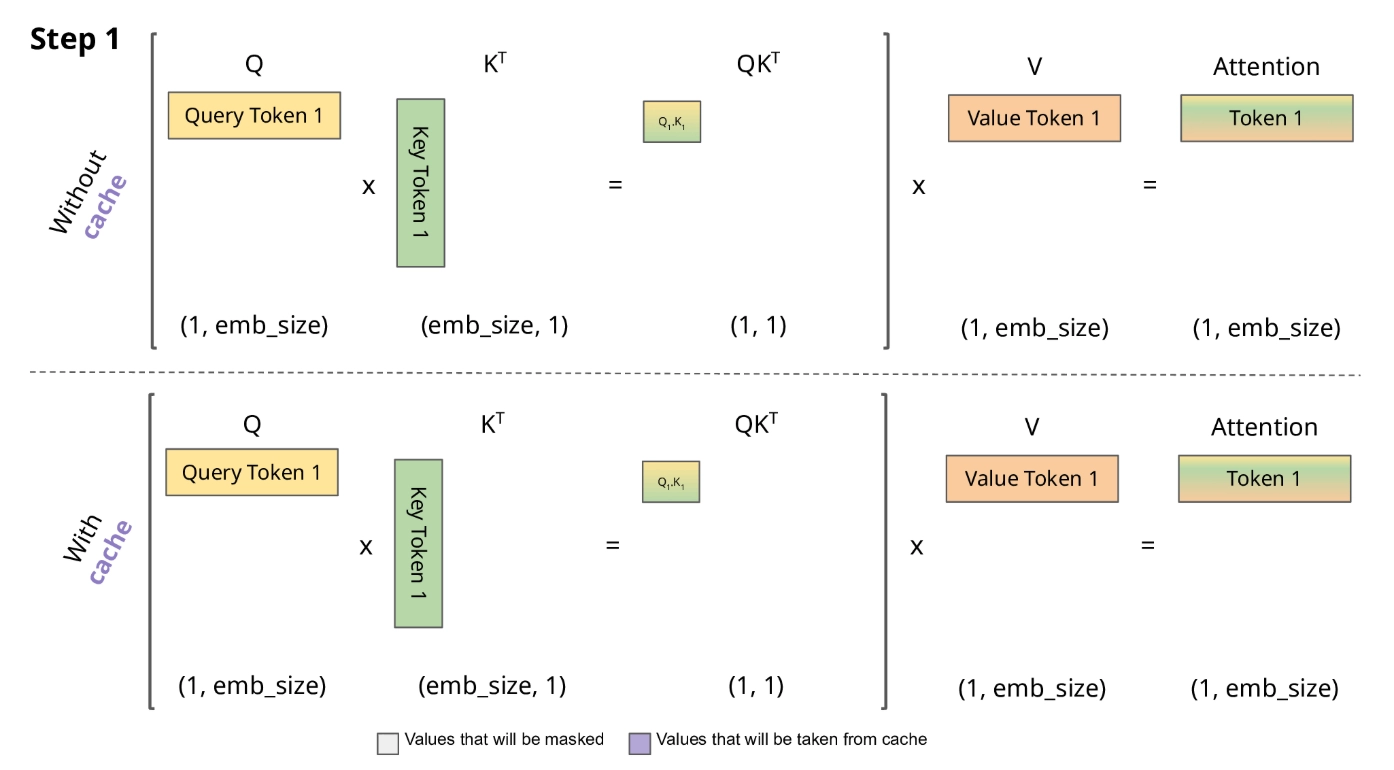
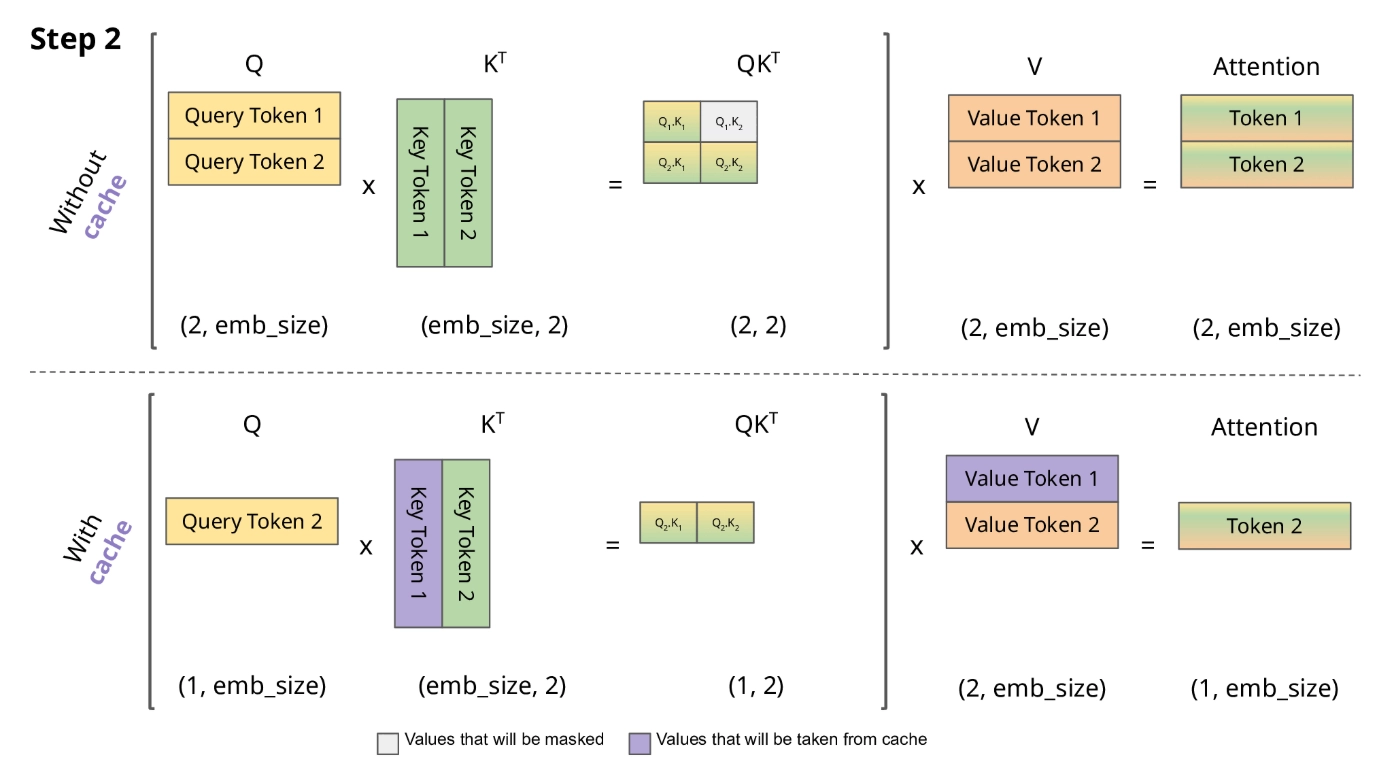
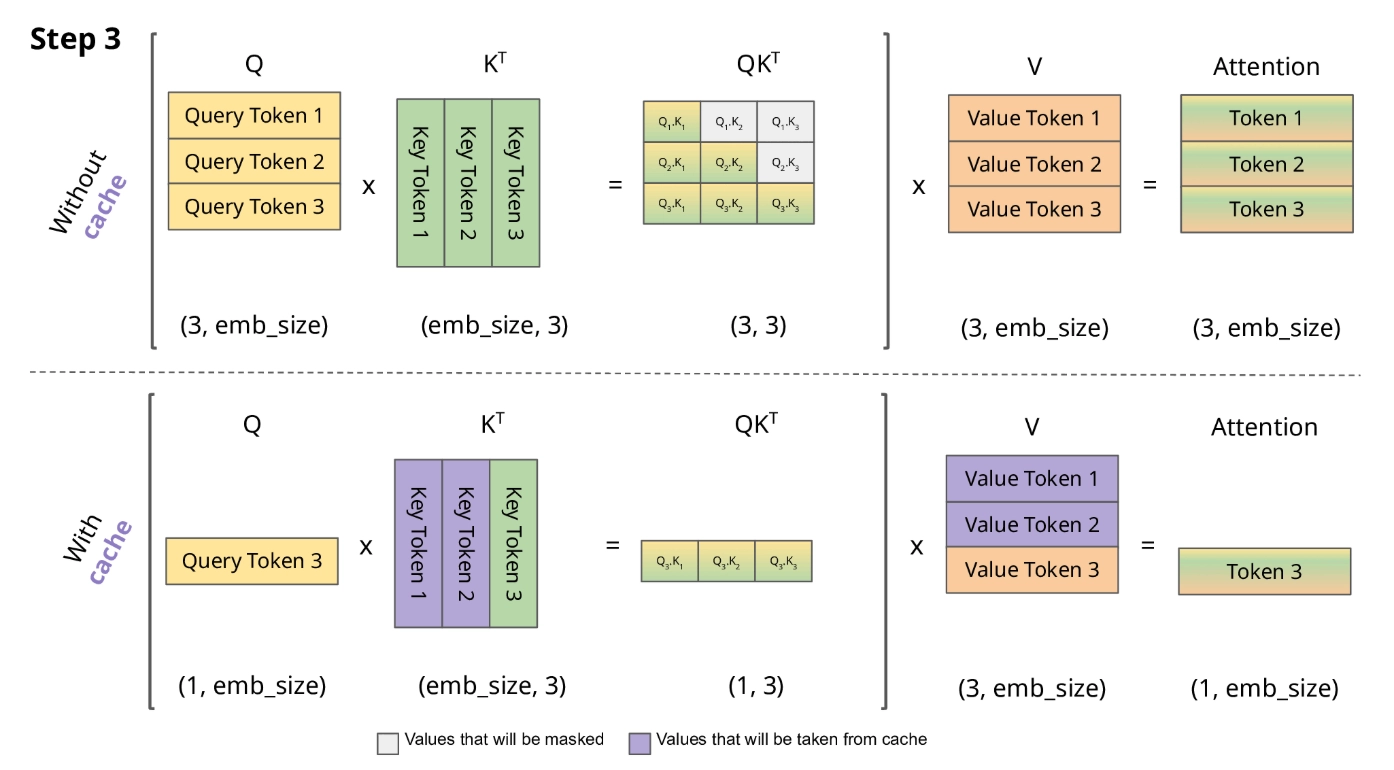
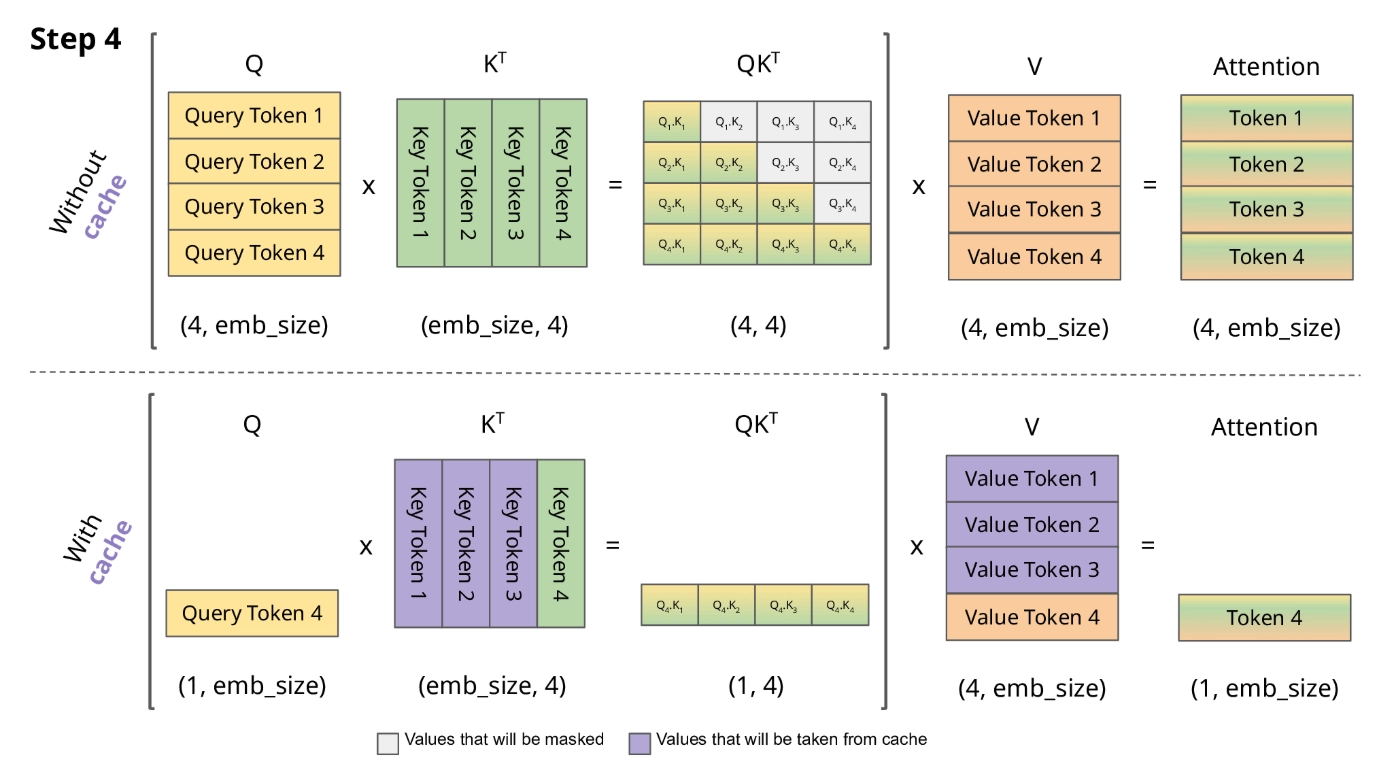
KV Cache 없이 LLM을 추론시키는 상황을 구체적으로 생각해 보자.
만약 KV Cache가 없다면, n번째 토큰을 생성할 때 1번부터 n-1번까지 모든 토큰의 K, V를 처음부터 다시 계산해야 한다. 총 N개의 토큰을 생성한다면, 전체 연산량은 에서 중복 연산이 지배적이게 된다 (은 레이어 수, 는 hidden dimension). 구체적으로, 1번째 토큰 생성 시 1회, 2번째 토큰 생성 시 2회, N번째 토큰 생성 시 N회의 forward pass가 필요하므로 총 회에 비례하는 연산이 발생한다. 이는 곧 latency(특히 TPOT, Time Per Output Token)가 수백 배 느려진다는 의미이다.
결론적으로, KV Cache는 LLM 추론을 실용적으로 가능하게 만드는 핵심 메커니즘이다. 이 메커니즘이 없으면 자주 쓰는 ChatGPT나 Cladue 그리고 Gemini 수준의 실시간 응답은 사실상 불가능하다.
3. KV Cache의 두 단계: Prefill vs Decode
LLM 추론은 두 단계로 나뉘며, 각 단계에서 KV Cache의 역할이 다르다.
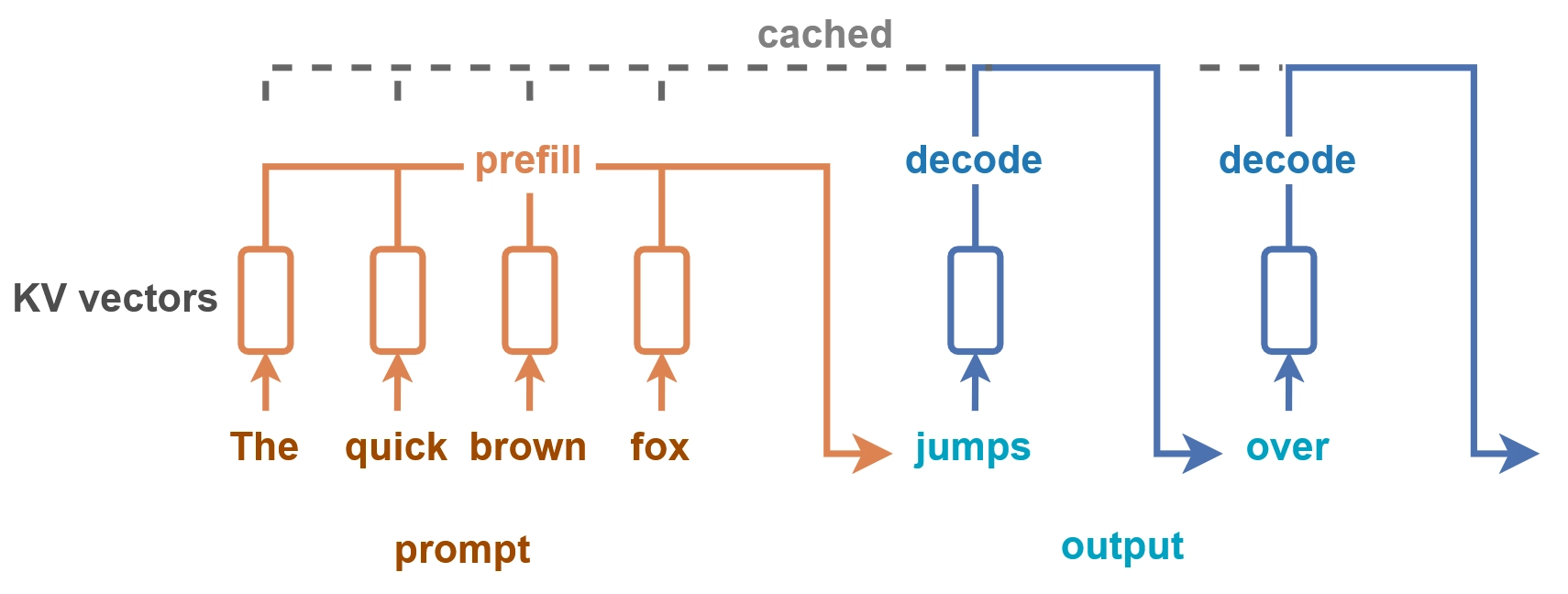
Prefill 단계 : 사용자의 입력 프롬프트(예: “”)를 한꺼번에 처리한다. 입력의 모든 토큰에 대해 K, V를 계산하고 이를 KV Cache에 저장한다. 이 단계는 compute-bound이다. 입력 토큰을 병렬로 한 번에 처리할 수 있어 GPU 연산 유닛을 효율적으로 활용한다.
Decode 단계 : 토큰을 하나씩 생성한다. 새 토큰의 Q를 생성하고, KV Cache에 저장된 모든 이전의 토큰의 K, V와 attention 연산을 수행한다. 새로 생성된 토큰의 K, V도 캐시에 추가한다. 이 단계는 memory-bound이다. 매 스텝마다 거대한 KV Cache를 GPU 메모리에서 읽어와야 하는데, 실제 연산량은 적어서 GPU 연산 유닛이 대부분 놀게 된다. 즉, 메모리 대역폭이 병목이다.
이 Prefill/Decode의 특성 차이가 시스템 최적화에서 매우 중요한 설계 포인트가 된다. Splitwise나 DistServe 같은 Prefill-Decode Disaggregation(프리필-디코딩 분리) 연구가 두 단계를 분리하여 별도 GPU에서 처리하는 이유는 바로 여기에 있다.
4. KV Cache의 메모리 사용량
KV Cache가 얼마나 많은 메모리를 차지하는지 계산해 보자.
한 토큰당 KV Cache 크기는 다음과 같다:
여기서 2는 K와 V 두 개를 의미하며, 은 레이어 수, 는 attention head 수, 는 head당 차원, 는 데이터 타입의 바이트 수(FP16이면 2바이트)이다.
LLaMA-2 70B 기준: 레이어 80개, GQA(Grouped Query Attention)를 사용하여 KV head가 8개이지만, 그래도 토큰당 약 2 x 80 x 128 x 2 = 328KB이고, 4,096 토큰이면 한 요청당 약 1.3GB이다. 동시에 수십~수백 개의 요청을 처리하려면 KV Cache만으로 GPU 메모리 수십 GB가 필요해진다.
모델 가중치는 모든 요청이 공유하지만, KV Cache는 요청별로 독립적으로 만들어진다. 따라서 동시 처리 요청 수(batch size)가 늘어나면 KV Cache 메모리가 선형으로 증가하고, 이것이 Serving System의 throughput(처리량)을 직접적으로 제한한다.
5. KV Cache의 기존 한계점
이러한 KV Cache에도 여러 한계점이 있다.
한계 1: Memory Fragmentation (메모리 단편화)
기존 시스템들은 요청이 들어오면 해당 요청의 최대 가능 시퀀스 길이만큼의 KV Cache 메모리를 미리 연속적으로 할당했다. 문제는 실제 생성되는 토큰 수를 미리 알 수 없다는 점이다. 최대 2,048 토큰을 할당했는데 실제로 200 토큰만 생성하면, 나머지 1,848 토큰에 대한 메모리는 낭비된다. 이것이 내부 단편화(internal fragmentation)이다. 또한, 다양한 길이의 요청들이 할당/해제를 반복하면서 외부 단편화(external fragmentation)도 발생한다. vLLM의 PagedAttention은 바로 이 문제를 해결하기 위해 제안되었다.
왜 외부 단편화가 발생할까?
KV Cache 없이 일반적인 메모리 할당 시나리오를 생각해 보자. GPU 메모리에 여러 요청의 KV Cache가 연속된 블록으로 할당된다. 예를 들어 총 20GB의 여유 메모리가 있고, 세 개의 요청이 들어온 상황이다:
[요청A: 3GB][요청B: 5GB][요청C: 4GB][빈 공간: 8GB]
여기서 요청B가 생성을 완료하고 메모리를 해제하면:
[요청A: 3GB][빈 공간: 5GB][요청C: 4GB][빈 공간: 8GB]
이제 총 빈 공간은 13GB이다. 그런데 새로운 요청D가 10GB의 연속 메모리를 필요로 한다면, 13GB의 빈 공간이 있음에도 5GB와 8GB로 나뉘어 있어서 할당이 불가능하다. 이것이 외부 단편화이다.
LLM 서빙 환경에서 이 문제가 특히 심각한 이유는, continuous batching 하에서 서로 다른 시점에서 시작되고 끝나는 수많은 요청이 계속 들어오고 나가기 때문이다. 짧은 응답을 생성하는 요청은 빨리 끝나서 중간에 빈 구멍을 만들고, 긴 응답을 생성하는 요청은 오래 남아서 빈 공간을 가로막는다.
vLLM의 PagedAttention이 이 문제를 해결하는 방식은 OS의 가상 메모리와 동일하다. KV Cache를 연속된 큰 블록이 아니라 작은 고정 크기 페이지(block)로 나누어 관리한다. 연속된 물리 메모리가 필요 없으므로, 흩어진 빈 공간도 활용할 수 있다.
한계 2: 메모리 용량 병목
앞서 계산한 것처럼 KV Cache의 메모리 소비는 상당하다. NVDIA A100 80GB GPU에서 70B 모델을 서빙하면, 모델 가중치가 이미 ~35GB(FP16 기준, 또는 INT4 양자화 시 ~17.5GB)를 차지하고, 남은 메모리로 처리할 수 있는 동시 요청 수가 제한된다. 특히 long-context 모델(128K, 1M 토큰)이 등장하면서 이 문제는 더욱 심각해진다. 128K 토큰 시퀀스의 KV Cache는 7B 모델에서도 약 64GB에 달한다.
한계 3: 중복 연산 및 캐시 공유의 어려움
여러 요청이 동일한 시스템 프롬프트를 공유하거나, multi-turn 대화에서 이전 대화의 KV를 재사용할 수 있음에도, 기존 시스템은 요청별로 독립적인 KV Cache를 유지했다. 같은 prefix에 대해 KV를 반복 계산하는 것은 연산과 메모리 모두의 낭비이다. SGLang의 RadixAttention은 이 문제를 다루며, prefix caching이라는 기법으로 공유 가능한 KV를 재활용한다.
Multi-turn 대화란 무엇인가?
Multi-turn 대화는 사용자와 LLM이 여러 차례 주고받는 대화를 의미한다.
[Turn 1] 사용자: KV Cache에 대해 설명해줘
LLM: KV Cache란...
[Turn 2] 사용자: 왜 이전 토큰의 K, V가 변하지 않아?
LLM: K는 X_i * W_K로 계산되므로...
[Turn 3] 사용자: 그러면 메모리 문제는 어떻게 해결해?
LLM: vLLM의 PagedAttention은...
Plain Text
복사
Multi-turn이 KV Cache와 관련하여 중요한 이유는, Turn 2에서 LLM이 응답하려면 Turn 1의 전체 대화 내용도 함께 입력으로 넣어야 하기 때문이다. Turn 3에서는 Turn 1 + Turn 2의 전체 내용이 입력에 포함된다. 즉, 대화가 이어질수록 입력 프롬프트가 점점 길어지고, 그에 따라 Prefill 단계에서 생성해야 할 KV Cache도 점점 커진다.
Turn 2의 입력은 “Turn 1의 전체 내용 + Turn 2의 사용자 질문”인데, Turn 1의 전체 내용에 대한 KV는 Turn 1에서 이미 계산한 적이 있다. 만약 Turn 1의 KV Cache를 버리지 않고 보관해 두었다면, Turn 2에서는 새로 추가된 사용자 질문 부분만 Prefill 하면 된다. 이것이 prefix caching 또는 KV cache reuse이다. SGLang의 RadixAttention이 바로 이러한 공유/재사용을 radix tree 구조로 효율적으로 관리한다.
“50대의 추교현이 20대의 추교현에게 감사할 수 있도록 하루하루 최선을 다해 살고 있습니다.”
The End.