

Introduction
1. 배경: 서버리스 환경과 트래픽 패턴의 중요성
Knative와 같은 서버리스(Serverless) 환경은 트래픽 유입량에 따라 파드(Pod)가 0개에서 수십 개로 자동 확장(Scale-to-Zero 및 Auto-scaling)되는 구조를 가진다. 따라서, 서버리스 시스템의 성능을 제대로 검증하기 위해서는 단순한 고정 부하가 아닌 실제 프로덕션 환경에서 발생하는 불규칙하고 급격한 트래픽 변화를 시뮬레이션해야 한다.
임의로 설정한 단순 반복 부하는 서버리스의 핵심인 오토스케일러(HPA, Horizontal Pod Autoscaling)의 동작을, 특히 Cold Starts(콜드 스타트)나 짧은 시간 동안 트래픽 양이 급격히 증가하는 Burst Traffic 처리 능력을 검증하는 데 한계가 있기 때문이다. 이를 해결하기 위해서는 실제 서버리스 워크로드 데이터인 Azure Functions Dataset을 활용하여 테스트 시나리오를 구성할 필요가 있다.
2. Why k6?
복잡한 트래픽 패턴을 구현하기 위해 이번 프로젝트에서는 대표적인 부하 테스트 도구인 JMeter 대신 k6를 선택했다. k6를 선택한 이유는 다음과 같다.
•
JMeter의 한계 (XML 설정의 복잡성):
JMeter는 GUI 기반으로 진입 장벽은 낮지만, 테스트 시나리오가 XML(eXtensible Markup Language) 파일(.jmx)로 저장된다. 이로 인해 코드 리뷰나 Git을 통한 버전 관리가 매우 어렵고, 조건문 분기 등 복잡한 로직을 구현하려면 GUI 설정 내에서 복잡한 구성을 거치거나 별도의 스크립트를 삽입해야 하는 등 이른바 “XML 설정 지옥”이라 부를 만한 비효율성이 존재한다.
•
k6의 강점 (코드로 로드 부하 테스트):
반면 k6는 JavaScript/TypeScript 코드로 시나리오를 작성한다. 개발자에게 익숙한 문법(if/else, Math.random)을 사용하여 복잡한 사용자 흐름을 쉽게 제어할 수 있으며, 테스트 스크립트를 애플리케이션 코드와 동일하게 관리할 수 있다. 또한, Go 언어 기반의 엔진을 사용하여 적은 리소스로도 서버리스 환경에 충분한 부하를 가할 수 있는 성능을 제공한다.
3. 목표: 실제 서버리스 워크로드 패턴의 k6 스크립트 구현하기
Azure Functions Dataset을 분석하여 도출한 실제 대표 트래픽 패턴을 k6 스크립트로 구현하고, 이를 통해 Knative 기반의 서버리스 워크플로우를 호출하는 과정을 설명하고자 한다.
구체적으로는 시계열 데이터 군집화 알고리즘인 K-Shape을 통해 대표적인 트래픽 패턴을 추출하고, 이를 k6의 설정값과 시나리오 로직에 적용하여 실제와 유사한 부하를 생성하는 방법을 다룬다.
Data Preparation & Pattern Derivation (데이터 준비 및 패턴 도출)
1. Azure Functions Dataset 활용
테스트 시나리오의 현실성을 확보하기 위해 Microsoft가 2019년 공개한 Azure Functions Dataset을 활용했다. 이 데이터셋은 실제 프로덕션 환경에서 수집된 서버리스 함수의 호출 빈도(Invocation Counts)를 분(minute) 단위로 기록한 시계열 데이터이다.
이 방대한 데이터 중에서 ‘함수 호출 빈도’ 데이터를 추출하여 분석 대상으로 삼았다. 이 데이터는 서버리스 환경 특유의 간헐적 호출(Intermittent Invocation), 급격한 트래픽 증가(Burst), 그리고 유휴 시간(Idle time) 등 실제 워크로드의 특성을 그대로 담고 있어 Knative 환경의 테스트에 최적이다.
2. 시계열 클러스터링: K-Means vs. K-Shape
추출한 수만 개의 함수 트래픽 데이터를 일일이 테스트할 수는 없으므로, 이를 대표할 수 있는 몇 가지 패턴으로 그룹화(Clustering)해야 한다. 일반적인 데이터 분석에서는 K-Means 알고리즘이 널리 쓰이지만, 이번 프로젝트에서는 시계열 데이터에 특화된 K-Shape 알고리즘을 채택했다. 그 이유는 다음과 같다.
•
K-Means의 한계 (유클리드 거리 기반):
K-Means는 데이터 포인트 간의 ‘유클리드 거리(Euclidean Distance)’를 기준으로 유사도를 판단한다. 이는 정적인 데이터에는 유효하지만, 시간의 흐름이 있는 데이터에서는 치명적인 단점이 있다.
예를 들어, 두 개의 트래픽 패턴이 똑같은 ‘상승 곡선’을 그리더라도, 발생 시점이 약간만 다르면(Time Shift) K-Means는 이를 서로 완전히 다른 데이터로 인식한다. 즉, 모양(Shape)이 같아도 x축(시간) 위치가 다르면 두 패턴이 다르다고 판단하는 오류를 범하기 쉽다.
•
K-Shape의 선정 이유 (형상 기반 거리 척도):
반면, K-Shape는 교차 상관(Cross-Correlation)에 기반한 거리 척도인 SBD(Shape-based Distance)를 사용한다. 이 방식은 시계열 데이터의 형상(Shape) 그 자체의 유사도에 집중한다. 데이터의 진폭을 정규화하고, 시점이 약간 어긋나더라도 전체적인 패턴 흐름이 비슷하면 같은 그룹(Cluster)으로 묶어준다.
따라서, “언제 부하가 들어오냐”보다 “부하가 어떤 형상으로 들어오냐”가 더 중요했기에 K-Means가 아닌 K-Shape가 우리 프로젝트에 적합했다.
3. 데이터 전처리: 로그 변환과 정규화
Azure Functions Dataset은 수만 개의 함수에 대한 호출 빈도(Invocation Counts)를 포함하고 있다. 하지만 원본 데이터를 그대로 클러스터링에 사용하기에는 크게 2가지 문제가 있었다.
1.
스케일의 차이: 어떤 함수는 분당 호출이 1~2회에 그치지만, 자주 호출되는 함수는 수천 회에 달한다. 절대적인 수치 크기보다 ‘패턴의 모양’을 기준으로 클러스터링하려면 스케일 조정이 필수적이다.
2.
0(Zero) 값의 처리: 호출이 없는(Invocation Counts = 0) 구간이 많은 서버리스 특성상, 일반적인 로그 변환은 불가능하다(log(0)은 정의되지 않음).
따라서, 우리는 모든 데이터에 대해 log(1 + Invocations) 변환을 수행했다. 위 그래프의 Y축에서 볼 수 있듯이, 이 변환을 통해 데이터의 스케일을 압축하고 0 값 문제를 해결하여, 트래픽이 적은 함수와 많은 함수를 동일한 선상에서 비교 분석할 수 있는 기반을 마련했다.
4. K-Shape 클러스터링 결과: 5가지 대표 패턴 추출
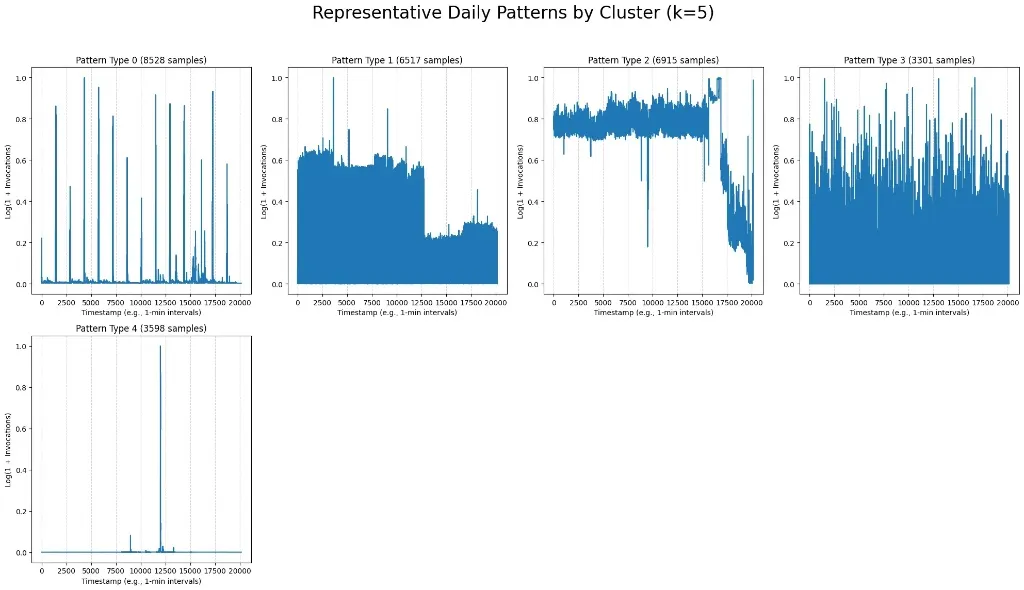
전처리가 완료된 시계열 데이터에 K-Shape 알고리즘을 적용하여 패턴을 추출했다. K-Means가 단순 거리를 측정한다면, K-Shape는 시계열의 형상(Shape) 유사도를 기반으로 군집화한다. k=5로 설정하여, 클러스터링한 결과, 위 이미지와 같이 실제 운영 환경을 대표하는 패턴 5가지가 도출되었다.
•
Pattern Type 0 (간헐적 스파이크):
평소에는 호출이 거의 없다가 특정 시점에 갑자기 치솟는 패턴이다.
•
Pattern Type 1 (계단적 하강):
일정 수준의 높은 부하가 유지되다가 특정 시점에 뚝 떨어지는 패턴이다.
•
Pattern Type 2 (지속적 고부하):
노이즈가 있지만 전반적으로 높은 트래픽을 꾸준히 유지하는 패턴이다.
•
Pattern Type 3 (변동성 과다):
예측이 매우 어렵고 변동 폭이 극심한 불규칙한 패턴이다.
•
Pattern Type 4 (단일 스파이크):
대부분의 시간 동안 호출이 0(Idle)이다가, 단 한 번의 극단적인 트래픽 스파이크가 발생하는 패턴이다.
이 5가지 패턴 중, 서버리스의 오토스케일링 성능을 검증하기에 가장 의미 있는 패턴은 Pattern Type 4(단일 스파이크)와 유사한 특성에 주목했다. 서버리스 환경에서 가장 대응하기 어려운 시나리오는 ‘아무런 트래픽이 없다가(Cold State) 갑자기 부하가 몰아치는(Burst)’ 상황이기 때문이다.
k6를 이용한 시나리오 구현
1. 외부 데이터 활용: Data-Driven Testing
함수 호출 시나리오를 하드코딩하지 않고, 실제 Azure Functions Dataset에서 추출된 ‘Pattern Type 4’에 해당되는 함수 호출량을 pattern_0.json 로 만들어서 이를 활용했다.
// pattern_0.json을 로드하여 배열 객체로 파싱
const patternData = JSON.parse(open("./pattern_0.json"));
JavaScript
복사
이렇게 하면 테스트 로직(Code)와 테스트 데이터(Data)가 분리되어 유지보수성이 높아진다. k6는 open() 함수를 제공하여 초기화 단계에서 로컬 파일을 가볍게 로드할 수 있다.
2. 동적 스테이지(stage) 생성
// 데이터 포인트를 k6 stages로 매핑하는 헬퍼 함수
function generateStages(data, timeUnit, scalingFactor) {
return data.map((value) => {
return {
duration: timeUnit, // "10s"로 설정하여 빠른 변화 유도
target: Math.round(value * scalingFactor), // x10 배율 적용
};
});
}
JavaScript
복사
가장 중요한 부분은 불러온 데이터를 k6의 실행 옵션인 stages로 변환하는 과정이다. 우리는 여기서 단순 변환을 넘어, 시스템에 제대로 부하를 걸기 위해서 두 가지를 적용했다.
•
시간 압축 (Time Compression):
원본 데이터는 1분 간격이지만, duration을 10초(”10s”)로 단축했다. 이는 트래픽의 변화 기울기를 가파르게 만들어, 오토스케일러가 급격한 변화에 얼마나 빠르게 반응하는지 확인하기 위함이다.
•
부하 증폭 (Load Amplification):
원본 데이터의 호출 수(Invocation counts)가 너무 낮을 경우 시스템에 충분한 스트레스를 주지 못할 수 있다. 따라서 데이터 값에 10배수(scalingFactor: 10)를 적용하여, 데이터가 ‘10’일 때 실제로는 ‘100명’의 가상 사용자(VU)를 투입하도록 설정했다.
3. 실제 유저 행동 모사
check(res, {
"Function returned 200 OK": (r) => r.status === 200,
// 응답 본문 파싱 및 논리적 정합성 검증
"Response contains correct condition": (r) => { ... }
});
JavaScript
복사
단순히 요청만 보내는 게 아니라, 실제 유저처럼 부하를 발생시키고 올바른 응답이 오는지 검증해야 한다:
•
랜덤 페이로드 분기:
모든 요청이 동일하면 서버 측 캐싱(Caching) 효과로 인해 정확한 성능 측정이 어려울 수 있다. Math.random()을 사용하여 50:50 확률로 서로 다른 데이터(’B’ or ‘C’)를 전송함으로써 실제와 유사한 무작위성을 부여했다.
•
정교한 응답 검증 (Check):
단순히 HTTP 200 OK만 확인하지 않고, 서버가 로직을 수행하고 올바른 결과를 반환했는지 확인하기 위해, 요청 시 보낸 조건(expectedCondition)과 응답받은 결과(received_condition)가 일치하는지 check 함수로 검증한다.
4. 전체 k6 스크립트
앞에서 설명한 데이터 로딩(Data Loading), 동적 스테이지 생성(Dynamic Stage), 그리고 유저 행동 모사(User Simulation) 로직을 모두 결합한 최종 k6 스크립트는 다음과 같다:
import http from "k6/http";
import { check, sleep } from "k6";
// 1. 데이터 준비: 외부 패턴 파일 로드 (Init Context)
// k6 실행 시 한 번만 수행되어 메모리에 로드됩니다.
const patternData = JSON.parse(open("./pattern_0.json"));
// 2. 헬퍼 함수: 데이터 포인트를 k6 stages로 변환
// timeUnit: 단계별 지속 시간 (예: "10s")
// scalingFactor: 부하 증폭 배율 (예: 10)
function generateStages(data, timeUnit, scalingFactor) {
return data.map((value) => {
return {
duration: timeUnit,
target: Math.round(value * scalingFactor),
};
});
}
// 3. 테스트 설정 (Configuration)
export const options = {
// 실제 패턴을 기반으로 하되, 변화를 극대화하기 위해 '10초 간격', '10배 증폭' 적용
stages: generateStages(patternData, "10s", 10),
insecureSkipTLSVerify: true,
};
// 테스트 대상 URL (Knative Service)
const WORKFLOW_A_URL = "https://{실제 워크로드 함수 URL}";
export default function () {
// 4. 유저 시뮬레이션: Payload 준비
const payloadB = JSON.stringify({ data: "B" });
const payloadC = JSON.stringify({ data: "C" });
const params = { headers: { "Content-Type": "application/json" } };
let payload;
let expectedCondition;
// 5. 랜덤 로직: 50% 확률로 요청 분기 (캐싱 방지 및 리얼리티 확보)
if (Math.random() < 0.5) {
payload = payloadB;
expectedCondition = "B";
} else {
payload = payloadC;
expectedCondition = "C";
}
// 6. 요청 전송
const res = http.post(WORKFLOW_A_URL, payload, params);
// 7. 결과 검증 (Status Code & Logic Check)
check(res, {
"Function returned 200 OK": (r) => r.status === 200,
"Response logic valid": (r) => {
try {
return r.json("received_condition") === expectedCondition;
} catch (e) {
return false;
}
},
});
sleep(0.5); // VU의 반복 속도 제어
}
JavaScript
복사
이 스크립트는 pattern_0.json에 정의된 트래픽 패턴을 읽어와 10초 단위로, 원본 데이터 대비 10배의 부하를 Knative 환경에 주입한다. 동시에 랜덤한 페이로드로 기능적인 정합성까지 함계 검증하는 스크립트이다.
“50대의 추교현이 20대의 추교현에게 감사할 수 있도록 하루하루 최선을 다해 살고 있습니다.”
The End.