


Ch 1-3. 소프트웨어 프로세스
소프트웨어 개발 모델
[주먹구구식 개발 모델 (Build-Fix Model)]
•
정의: 요구사항 분석, 설계 단계 없이 일단 개발에 들어간 후 만족할 때까지 수정
•
단점: 정해진 개발 순서가 없기에
◦
계획이 정확하지 않음
◦
관리자는 프로젝트 진행 상황 파악에 어려움
◦
개발 문서가 없기에 개발 및 유지보수에 어려움
[폭포수 모델 (Waterfall Model)]
•
정의:
◦
순차적으로 소프트웨어를 개발하는 전형적인 개발 모델
◦
대부분의 소프트웨어 개발 프로젝트의 기본적 모델, 가장 많이 사용되는 모델
◦
소프트웨어 개발의 전 과정을 체계적으로 나눠 순차적으로 접근
•
장점:
◦
각 단계별로 정형화된 접근 가능
◦
체계적인 문서화를 통해 명확한 프로젝트 진행 가능
•
단점:
◦
앞 단계가 완료될 때까지 다음 단계들은 대기
◦
실제 작동되는 SW를 개발 후반부에 확인 가능하기에 고객이 요구사항 만족 여부를 확인하기까지 많은 시간 요소
[원형 모델 (Prototyping Model)]
•
정의:
◦
폭포수 모델의 단점을 보완한 모델
◦
점진적으로 SW를 개발해 나가는 접근 방법
◦
원형(Prototype)을 만들어 고객과 사용자가 함께 평가하며, SW 요구사항 정제
•
목적: 프로토타입을 빠르게 개발하여 고객과 검증하는 것
◦
고객으로부터 피드백을 받은 후, 원형 폐기
◦
SW 기능 중 중요한 부분만 구현하여 피드백을 얻은 후, 지속적으로 발전시켜 완제품을 제작
[나선형 모델 (Spiral Model)]
•
정의:
◦
폭포수 모델과 원형 모델의 장점을 수용하고 위험 분석(Risk analysis)을 추가한 점증적 개발 모델
◦
프로젝트 수행 시, 발생하는 위험을 관리하고 최소화하는 것이 목적
•
특징:
◦
나선상의 각 원은 소프트웨어 개발의 점증적 주기 표현
◦
엔지니어가 프로젝트 성격이나 진행 상황에 따라 단계 구분
•
장점:
◦
프로젝트 모든 단계에서 기술적 위험을 직접 고려할 수 있어서 사전 위험 감소
◦
요구사항 변경, 제품 개발 지연 등에 효과적으로 대응 가능
•
단점:
◦
프로젝트 소요 기간 증가 가능성 및 정확한 위험 분석의 필요성
◦
폭포수, 원형 모델에 비해 상대적으로 복잡하여 프로젝트 관리의 어려움
Ch 4-6. 소프트웨어 프로젝트 계획
기능 점수
[기능 점수 (Function Point)]
•
정의: 시스템을 구현한 기술에 독립적이고, 사용자에 의해 식별되는 기능에 기반하여 전체 시스템의 크기를 측정하는 척도
•
장점:
◦
개발에 사용된 기술, 개발 환경(개발 언어, 도구 등) 및 개발자의 능력에 독립적
◦
사용자 요구사항만으로 측정할 수 있어 개발 초기에 산정 가능
◦
개발은 물론 계획, 운영 등 전 단계에서 측정 가능
•
단점:
◦
측정에 비용과 시간이 소요
◦
프로젝트 초기 단계에 모든 요구사항을 다 파악하기 어렵기에 정확한 예측 어려움
EVM
[EVM의 개요]
•
정의:
◦
프로젝트가 계획대로 잘 진행되고 있는지를 통제하기 위한 모니터링 관리 기법
◦
프로젝트의 일정 상태, 비용 상태 그리고 완료된 작업량을 비용화하여 계획 대비 실적을 비교 및 평가함으로써 프로젝트의 성과와 진행률을 정량적으로 관리
•
특징:
◦
비용과 시간을 모두 화폐 단위로 통합하여 정량화
▪
프로젝트의 일정, 비용 그리고 완료를 모두 금액으로 환산
▪
특정 시점까지 완료된 작업량을 비용화하여, 계획된 비용과 비교 평가
[EVM의 기본 용어]
•
BCWS (Budgeted Cost of Work Scheduled)
◦
PV(Planned Value)
◦
계획된 작업량의 계획된 비용
•
BCWP (Budgeted Cost of Work Performed)
◦
EV(Earned Value)
◦
수행한 작업의 계획된 비용
•
ACWP (Actual Cost of Work Performance)
◦
AC(Actual Cost)
◦
수항한 작업의 실제 비용
•
BAC (Budget at Completion)
◦
BCWS의 합
◦
전체 작업에 대한 계획된 비용
•
EAC (Estimate at Completion)
◦
ACWP + {(BAC - BCWP) / CPI} (남은 작업량에 대한 예측된 비용)
◦
전체 작업이 완료되는 데 예측되는 실제 비용
•
SV (Schedule Variance)
◦
BCWP - BCWS
◦
계획된 작업량과 실제 수행된 작업량의 차이
◦
마이너스 값: 일정 지연
•
CV (Cost Variance)
◦
BCWP - ACWP
◦
계획된 비용과 실제 비용의 차이
◦
마이너스 값: 비용초과
•
VAC (Variance at Completion)
◦
VAC = BAC - EAC
◦
마이너스 값: 전체 작업을 완료할 때, 계획보다 비용이 초과됨
◦
플러스 값: 전체 작업을 완료할 때, 계획보다 비용이 남음
•
SPI (Schedule Performance Index)
◦
SPI = BCWP / BCWS
◦
SPI < 1 : 일정 지연
•
CPI (Cost Performance Index)
◦
CPI = BCWP / ACWP
◦
CPI < 1 : 비용 초과
Ch 7-8. 소프트웨어 요구사항 분석
요구사항
[요구사항의 분류]
•
기능적 요구사항 (Functional Requirements)
◦
목표로 하는 제품의 구현을 위해 소프트웨어가 가져야 하는 기능적 속성
◦
예) 워드 프로세서에서 파일 저장 기능, 편집 기능, 보기 기능 등
•
비기능적 요구사항 (Non-Functional Requirements)
◦
제품의 품질 기준을 만족시키기 위해 소프트웨어가 가져야 하는 성능, 사용성, 안전성과 같은 품질 속성
◦
예) 응답 시간, 처리량, 사용의 용이성, 신뢰도, 보안성, 안전성 등
[요구사항 분석]
•
구조적 분석 (Structured Analysis)
◦
시스템의 기능을 중심으로 분석
◦
시스템의 기능을 정의하기 위해서 프로세스들을 도출하고, 도출된 프로세스 간의 데이터 흐름 정의
◦
자료 흐름도 (Data Flow Diagram)
•
객체지향 분석 (Object-Oriented Analysis)
◦
사용자 중심의 시나리오를 중심으로 분석
◦
유스케이스 모델 (Use-case Model)
•
정보공학 분석 (Data-Oriented Analysis)
◦
자료 또는 데이터를 중심으로 분석
◦
자료를 처리학 위해 필요한 기능을 도출하고 정체
◦
ER 다이어그램
[요구사항 검증]
•
무결성(correctness) 및 완전성(completeness): 사용자 요구를 에러 없이 완전하게 반영하고 있는가?
•
일관성(consistency): 요구사항이 서로 간에 모순되지 않는가?
•
명확성(unambiguous): 요구분석의 내용이 모호함 없이 모든 참여자들에 의해 명확하게 이해될 수 있는가?
•
기능성(functional): 요구사항 명세서가 “어떻게”보다 “무엇을”에 관점을 두고 기술되었는가?
•
검증 가능성(verifiable): 기술된 내용이 사용자의 요구를 만족하는가? / 개발된 시스템이 요구사항 분석 내용과 일치하는지를 검증할 수 있는가?
•
추적 가능성(traceable): 요구사항과 설계 문서를 추적할 수 있는가?
유스케이스 기반 요구사항 분석
[요구 분석 단계의 작업]
•
구조적 분석: 기능(프로세스) 중심으로 요구사항 분석 using DFD(Data Flow Diagram)
•
객체지향 분석: 사용자 상호작용 중심으로 요구사항 분석 using 유스케이스 다이어그램
•
정보공학 분석: 정보나 자료를 중심으로 요구사항 분석 using ER 다이어그램
[모델링 방법론]
•
부치 방법론 (4+1 뷰)
◦
시스템을 여러 개의 뷰(View)로 분석하여 모델링
◦
유스케이스 뷰 + 논리 뷰, 구현 뷰, 프로세스 뷰, 배포 뷰
•
야콥슨의 OOSE (Object Oriented Software Engineering)
◦
유스케이스를 강조한 방법론
◦
사용자와 상호작용하는 시스템의 요구사항을 정의
◦
정의된 유스케이스를 개발, 테스트, 검증 단계에서 사용
•
럼바우 OMT (Object Modeling Technique)
◦
시스템을 기술하기 위해 3가지 모델 사용
▪
객체 모델 (Object Model): 정적 구조 (클래스, 객체)
▪
기능 모델 (Functional Model): 데이터 변환 (DFD)
▪
동적 모델 (Dynamic Model): 제어 흐름 및 상호 작용 (상태 및 동작)
유스케이스 다이어그램
[시스템 (System)]
•
정의: 만들고자 하는 프로그램을 나타냄
•
표기: 사각형 틀로 시스템 명칭을 안쪽 상단에 작성함
[액터 (Actor)]
•
정의: 시스템의 외부에 있고, 시스템과 상호작용을 하는 사람 또는 다른 시스템
•
표기: 원과 선을 조합한 사람으로 표현
[유스케이스 (Usecase)]
•
정의: 시스템이 액터에게 제공해야 하는 기능
•
표기: 타원으로 표시하고, 이름은 “~한다”와 같이 동사로 표현
[관계 (Relationship)]
•
정의: 액터와 유스케이스 사이의 의미 있는 관계
•
종류:
◦
연관 관계 (Association)
▪
유스케이스와 액터를 실선으로 연결
▪
상호작용이 있음을 표현
◦
의존 관계 (Dependency)
▪
포함 관계 (Include)
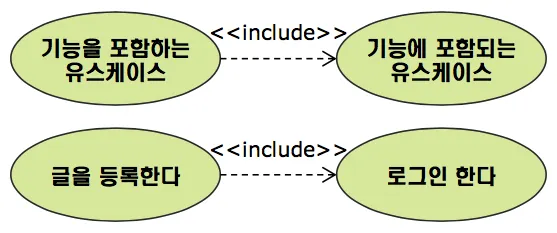
•
하나의 유스케이스가 다른 유스케이스의 실행을 전제로 실행될 때 형성되는 관계
•
A → B: B가 실행되어야 A가 실행됨
▪
확장 관계 (Extend)
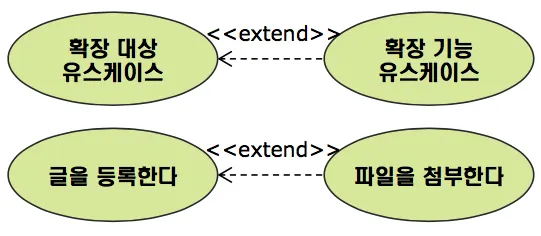
•
확장 기능(Extending) 유스케이스와 확장 대상(Extended) 유스케이스 사이에 형성되는 관계
•
A → B: B를 실행할 때, A도 실행할 수 있음
◦
일반화 관계 (Generalization)
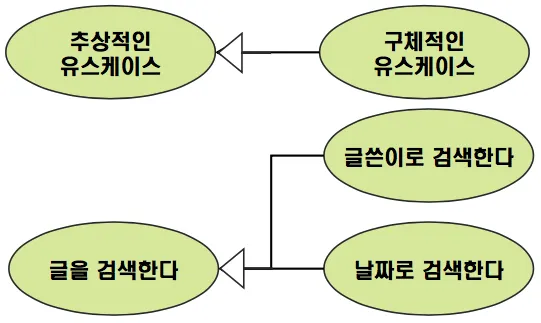
▪
유사한 유스케이스들 또는 액터들을 모아 추상화함으로써 이해도를 높이기 위한 관계
▪
A → B: 추상적인 A들은 구체적인 B로 포함될 수 있음
[유스케이스 다이어그램 작성 순서]
1.
시스템 및 액터 식별
•
시스템 식별
•
사용자의 역할 식별
•
외부 시스템 식별
2.
유스케이스 식별
•
액터가 요구하는 서비스 식별
•
액터가 시스템과 상호작용하는 행위 식별
3.
관계 정의
•
액터와 유스케이스 간 일반화/연관 관계 정의
•
유스케이스 간 포함/확장 관계 정의
Ch 9. 소프트웨어 구조 설계
소프트웨어 설계
[상위 설계와 하위 설계]
•
상위 설계 (High-Level Design)
◦
아키텍처 설계(Architecture Design), 예비 설계(Preliminary Design) 라고도 함
◦
소프트웨어 구성 모듈들 간의 관계로 표현되는 시스템의 전체적인 구조
◦
아키텍처 설계(시스템 구조도), 외부 파일 및 DB 설계(레코드 레이아웃, ERD), 화면 인터페이스 설계 등이 포함됨
•
하위 설계 (Low-Level Design)
◦
모듈 설계(Module Design), 상세 설계(Detail Design)라고 함
◦
시스템 구성 요소들의 내부 구조, 동적 행위 등을 결정함
◦
각 구성 요소의 제어와 데이터들 간의 연결에 대한 정의
◦
모듈 설계, 알고리즘 설계, 자료구조 설계 등이 포함됨
[설계 방식]
•
프로세스 지향 설계 (Process Oriented Design)
◦
업무의 처리절차를 중심으로 설계의 구성 요소들을 구분
◦
어떠한 절차를 거쳐서 작업을 수행하는가, 어떠한 입출력 자료를 생성하는가에 초점
•
객체지향 설계 (Object Oriented Design)
◦
시스템을 이루는 실제 객체 요소를 중심으로 설계
◦
자료구조와 그에 대한 연산을 묶어서 구성되는 객체들을 정의하고, 객체 간 상호작용의 기본이 되도록 설계
[설계 원리]
•
추상화 (Abstraction)
◦
정의:
▪
특정 목적과 관련된 필수 정보만 추출하여 강조하고
▪
관련이 없는 세부 사항을 생략함으로써 본질적인 문제에 집중할 수 있도록 하는 작업
◦
단계: 상위 레벨에서의 설계를 먼저 고려하고, 점차 하위 레벨로 구체화
◦
종류:
▪
과정 추상화 (Procedure Abstraction)
•
입력 자료를 출력 자료로 변환하는 과정을 추상화
•
수행 과정의 자세한 단계를 고려하지 않고, 상위 수준에서 수행 흐름만 먼저 설계
▪
데이터 추상화 (Data Abstraction)
•
데이터 구조를 대표할 수 있는 표현으로 대체하는 것
•
예) “연, 월, 일” 데이터 타입을 단순히 “날짜”로 추상화하는 것
▪
제어 추상화 (Control Abstraction)
•
제어 로직을 대표할 수 있는 표현으로 대체하는 것
•
예) “윤년이면, 윤년 요일 계산을 수행한다.”, “평년이면, 평년 요일 계산을 수행한다.”
⇒ “윤년 여부에 따라 요일 계산을 수행한다.” 로 추상화 가능
•
단계적 분해 (Stepwise Refinement)
◦
정의: 문제를 상위 개념부터 더 구체적인 단계로 분할하는 하향식 기법의 원리
◦
과정:
▪
문제를 하위 수준의 독립된 단위로 나누는 것
▪
분해된 문제의 자세한 내용은 가능한 뒤로 미루는 것
▪
점증적으로 구체화 작업을 계속함
•
모듈화 (Modularization)
◦
정의: 수행 가능 명령어, 자료구조 또는 다른 모듈을 포함하고 있는 독립 단위
◦
특성:
▪
독립적으로 컴파일 및 동작
▪
다른 모듈 사용 가능
▪
다른 프로그램에서 사용 가능
▪
모듈의 크기: 모듈 내의 응집력은 높게, 모듈 간의 결합력은 약하게
◦
응집력 (Cohesion):
▪
정의:
•
모듈을 이루는 각 요소들의 서로 관련되어 있는 정도
•
강한 응집력을 가진 모듈을 만드는 것이 모듈 설계의 목표
▪
응집력 정도:
1.
기능적 응집 (Functional Cohesion)
•
한 모듈이 하나의 기능을 수행하는 데 관련된 요소들만 포함하고 있는 경우
•
예) 판매 총액 계산
2.
순차적 응집 (Sequential Cohesion)
•
모듈 내 한 구성 요소의 출력이 다른 구성 요소의 입력이 되는 경우
•
예) 판매 총액 계산 후, 평균 값을 구하는 경우
3.
교환적 응집 (Communication Cohesion)
•
한 모듈 내에 2개 이상의 기능이 존재하고 단계별로 수행되는 경우
각 기능은 동일한 입력 자료를 사용하면서도 서로 다른 출력을 생성
•
예) 하나의 모듈 내의 특정 데이터를 저장소에 저장, 동일한 데이터를 프린터로 출력하는 경우
4.
절차적 응집 (Procedural Cohesion)
•
모듈 안의 요소들이 서로 연관이 있고, 특정 순서에 의해서만 수행되는 경우
•
예) DB로부터 부품 번호를 읽은 후, 이력 파일에 수리 기록을 갱신
5.
시간적 응집 (Temporal Cohesion)
•
한 모듈 내에서 같은 시기에 수행되는 요소들을 모아놓은 형태
•
예) 변수 초기화, 드라이버 초기화로 구성된 특정 프로그램의 초기화 모듈
6.
논리적 응집 (Logical Cohesion)
•
관계가 있는 요소들로 형성되고, 하나 이상의 작업 및 기능을 담고 있는 형태
•
예) 하나의 모듈이 데이터 파일을 입력, 삭제, 업데이트하는 경우
7.
우연적 응집 (Coincidental Cohesion)
•
아무 관련 없는 요소들로 모듈이 형성되는 경우
•
예) 하나의 모듈 내에 관계 없는 요소 및 작업들이 혼재하는 경우
◦
결합력 (Coupling):
▪
정의:
•
모듈 간에 연결되어 상호 의존하는 정도
•
약한 결합도를 갖는 모듈을 만드는 것이 목표
▪
결합도 정도:
1.
자료 결합 (Data Coupling)
•
모듈 간의 인터페이스가 같은 성질의 자료 요소로만 구성된 경우
•
예) 회원 등록 관련 모듈 간 전달 파라미터로 회원 관련 데이터인 아이디, 비밀번호, 주민번호가 사용되는 경우
2.
구조 결합 (Stamp Coupling)
•
모듈 간의 인터페이스로 배열이나 레코드 등의 자료 구조가 전달되는 경우
•
예) 모듈 A가 모듈 B의 C란 데이터를 참조하는 데 있어서, 하나의 배열 또는 레코드 안에 있는 D, E, F도 함께 참조하는 경우
3.
제어 결합 (Control Coupling)
•
한 모듈이 다른 모듈에게 제어 요소(function code, switch, tag 등)를 전달하는 경우
•
예) 모듈 A가 모듈 B의 취할 액션을 결정하는 경우
4.
공통 결합 (Common Coupling)
•
여러 모듈이 공통 자료(전역 자료) 영역을 사용하는 경우
•
예) 모듈 A와 모듈 B가 전역 변수 C를 참조하는 경우
5.
내용 결합 (Content Coupling)
•
한 모듈이 다른 모듈의 일부분을 직접 참조 또는 수정하려는 경우
•
예) 모듈 A가 모듈 B의 지역 변수를 참조하는 경우 / GoTo 사용하는 경우
아키텍처 유형
[계층식 (Layered)]
•
정의:
◦
여러 모듈들을 계층적으로 배치
◦
하위 모듈의 그룹으로 나눌 수 있는 구조화된 시스템에서 활용
◦
하위 모듈들은 특정한 수준의 추상화, 각 계층은 상위 계층에 서비스 제공
•
계층:
◦
인터페이스 계층
▪
사용자에게 정보를 제공, 사용자의 명령을 해석
◦
응용 & 도메인 계층
▪
소프트웨어에서 요구되는 작업 정의
▪
룰 체킹, 처리, 통지 등의 동작 제어하는 객체 포함
◦
인프라스트럭쳐 계층
▪
상위 계층을 지원하는 일반화된 기술적 기능 제공
▪
저장, 검색, 질의 메시지 전송 등
[클라이언트-서버 (Client-Server)]
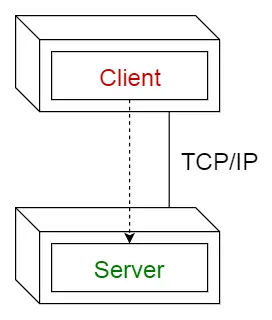
•
계층:
◦
클라이언트:
▪
사용자로부터 입력을 받아 범위 체크
▪
데이터베이스 트랜잭션을 구동하여 필요한 모든 데이터 수집
◦
서버:
▪
트랜잭션을 수행
▪
데이터의 일관성 보장
[모델-뷰-컨트롤러 (MVC)]
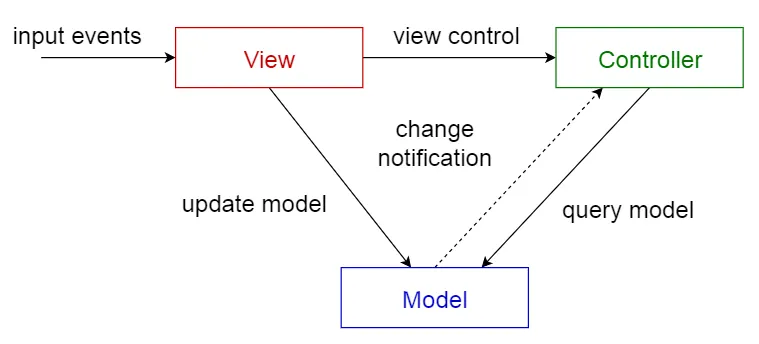
•
계층:
◦
모델 (Model): 도메인의 지식을 저장 및 보관
◦
뷰 (View): 사용자에게 보여줌
◦
제어 (Control): 사용자와의 상호작용을 관리
•
분리 이유: 사용자 인터페이스, 즉 뷰와 제어가 도메인 지식을 나타내는 모델보다는 더 자주 변경될 수 있기 때문임
Ch 10-11. 소프트웨어 테스팅
테스팅 개요 및 원칙
[소프트웨어 테스트 개요]
•
SW 테스트의 정의:
◦
남아 있는 결함이나 오류를 발견하기 위한 활동
◦
오류가 없음을 확인시켜 주지는 않음
◦
사전에 오류를 예방하는 것이 매우 중요함
◦
고객의 요구를 만족시키는지 확인
•
소프트웨어 테스트의 목적:
◦
잠재적 오류와 결함의 발견
◦
요구사항의 준수 여부(기능/비기능) 확인
◦
소프트웨어 신뢰성 등 품질 확인
◦
고객 만족도 향상
[소프트웨어 테스팅의 원칙]
•
살충제 패러독스 (Pesticide Paradox):
◦
정의:
▪
동일 테스트 케이스로 동일 테스트를 반복하는 경우, 새로운 버그를 찾아내기 어려움
▪
잠재된 많은 결함을 발견하기 위해서는 테스트 케이스를 정기적으로 리뷰/개선/추가할 필요가 있음
◦
해결 방법:
▪
테스트 기법의 다앙성 적용: 동일한 테스트를 반복하는 대신, 블랙박스/화이트박스 테스트, 성능 테스트 등 다양한 테스트 기법을 조합하여 사용해야 됨
▪
테스트 자동화: 자동화 도구를 사용하여 반복적인 테스트 작업을 자동화하면서도, 정기적으로 테스트 스크립트를 업데이트하고 새로운 시나리오를 추가해야 됨
▪
리스크 기반 테스트: 중요도가 높은 영역이나 결함이 발생할 가능성이 높은 영역에 대해 더 집중적으로 테스트를 수행하는 리스크 기반 테스트를 도입해야 됨
테스팅 유형
[테스트에 대한 시각]
•
검증 (Verification):
◦
개발과정 테스트 - Are we building the product right?
◦
개발 단계의 산출물이 설정된 조건을 만족하는지 평가
•
확인 (Validation):
◦
결과를 테스트 - Are we building the right product?
◦
명시된 요구사항들을 만족하는지 평가
[테스트 목적]
•
회복 테스트 (Recovery): 고의적 실패 유도
•
보안 테스트 (Security): 불법적인 오남용 및 침해
•
스트레스 테스트 (Stress): 대형 또는 복합 데이터 구조, 과부하 테스트, 장기 테스트
•
성능 테스트 (Performance): 응답시간, 처리량, 속도
•
회귀 테스트: 변경 또는 수정이 새로운 오루를 발생시키 않음을 확인
[V-Model]
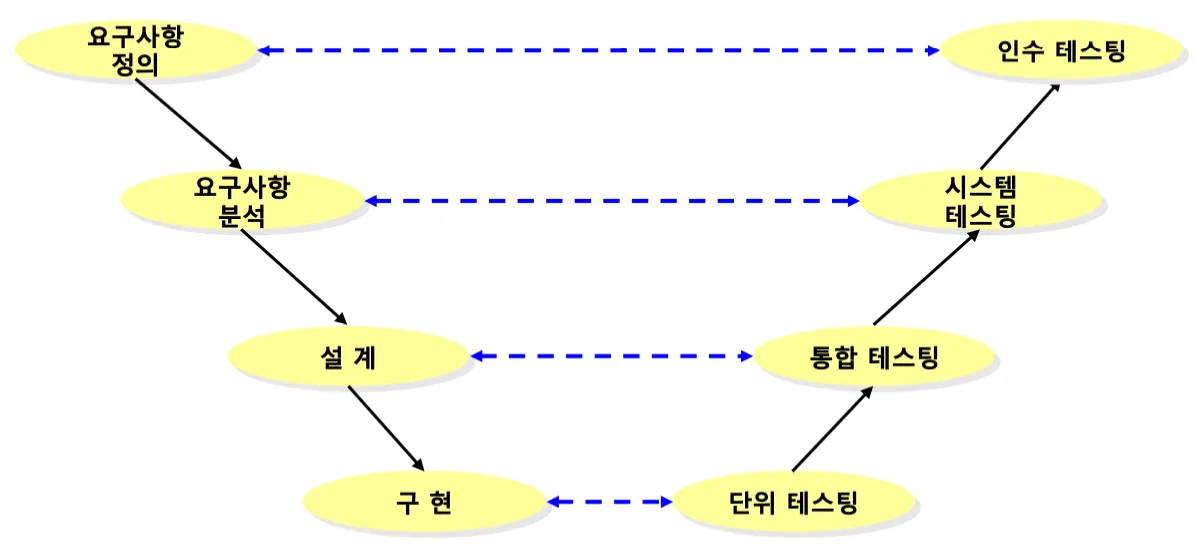
•
테스트 작업의 유형과 관련된 생명 주기를 모형화한 것
•
V-Model은 실행 작업과 그 작업 결과의 검증에 초점을 둠
•
각 테스트 단계에서 오류를 발견하면, 왼쪽의 요구사항 정의 및 분석, 설계 및 구현으로 되돌아갈 수 있는 추적성(traceability)을 보장
테스팅 단계
[단위 테스팅 (Unit Testing)]
•
정의: 구현 단계에서 각 모듈이 완성되었을 경우, 개별적인 모듈을 테스팅
•
테스팅의 주체: 해당 모듈의 개발자
◦
화이트박스/블랙박스 테스팅 모두 가능
•
테스트할 모듈을 단독적으로 실행할 수 있는 환경 필요
◦
스텁(Stub): 테스팅 대상 모듈에서 호출하는 모듈
◦
드라이버(Driver): 테스팅 대상 모듈을 호출하는 환경
[통합 테스팅 (Integration Testing)]
•
정의:
◦
모듈을 통합하는 단계에서 수행되는 테스팅
◦
모듈 간의 상호작용을 검사하는 테스팅
•
통합 방법:
◦
빅뱅 기법 (Big Bang):
▪
모듈을 한꺼번에 통합하여 테스팅을 하는 방법
▪
오류가 발생하였을 경우, 어느 부분에서 오류가 났는지 찾기가 어려움
◦
하향식 기법 (Top-Down):
▪
가장 상위 모듈부터 하위 모듈로 점진적으로 통합하는 방법
▪
상위 모듈 테스팅 시, 하위 모듈에 대한 스텁(Stub)이 필요함
◦
상향식 기법 (Bottom-Up):
▪
하위 모듈부터 테스팅하고 상위 모듈로 점진적으로 통합하는 방법
▪
하위 모듈 테스팅 시, 상위 모듈에 대한 테스트 드라이버(Driver)가 필요함
[인수 테스팅 (Acceptance Testing)]
•
정의: 시스템이 사용자에게 인수되기 전, 사용자에 의해 실시되는 테스팅
•
종류:
◦
알파 테스팅: 개발자 환경에서 사용자 실시
◦
베타 테스팅: 실제 사용자 환경에서 실시
•
인수 테스팅을 통과해야만, 시스템이 정상적으로 사용자에게 인수되고 프로젝트는 종료됨
[시스템 테스팅 (System Testing)]
•
모듈이 모두 통합된 후, 사용자의 요구사항이 만족되었는지 검사하는 테스팅
•
고객에게 시스템을 전달하기 전, 시스템을 개발한 조직이 주체가 되는 마지막 테스팅
•
테스팅 대상: 요구사항 명세서를 기초하여 사용자의 기능 요구사항 및 보안, 성능, 신뢰성 등의 비기능 요구사항
정적 테스트
[동료 검토 (Peer Review)]
•
정의:
◦
개발 동료들이 결함의 검출을 위해 소프트웨어 작업 산출물을 검토하는 작업
◦
개발자가 자신의 동료들이 완료한 작업을 검토하는 것
•
목적: 사용자 인터페이스. 요구 명세서, 아키텍처, 기타 기술적 산출물의 품질 보증
[인스펙션 (Inspection)]
•
정의: 엄격한 절차에 따라 공식적으로 진행되는 코드나 문서의 검토 과정
•
특징:
◦
사람에 의해서 수행되는 테스트로 개발 초기에 오류를 발견하여 개발 비용을 줄이기 위함
◦
인스펙션 절차를 사용하여 평균 비용 65~80% 감소
◦
테스터들 간 회의 활동을 통해 오류를 찾음
◦
다음 프로세스로 넘어가기 전, 오류를 수정하기 위함
[워크스루 (Walkthrough)]
•
정의: 작성자가 자신의 코드나 문서를 팀 앞에서 설명하고, 팀이 이에 대해 의견을 제시하는 검토 과정
•
특징:
◦
약간 공식적: 인스펙션보다는 덜 공식적으로, 일정한 절차에 따라 진행됨
◦
작성자 주도: 작성자가 자신의 작업을 직접 설명하며 팀의 피드백을 받음
◦
교육적 목적: 팀원 간의 지식 공유와 교육을 목적으로 할 때도 많음
동적 테스팅
[블랙박스 테스팅 (Black-Box Testing)]
•
정의:
◦
요구사항 명세서를 참조하면서 수행하는 테스팅
◦
소스 코드 자체의 로직에는 관심이 없고 입출력 값에만 관심이 있음
•
방법:
◦
구문 테스팅 (Syntax Testing)
▪
블랙박스 테스팅 중 가장 단순한 방법
▪
입력 데이터가 미리 정의된 데이터 유형에 적합한지를 검증하는 방법
▪
즉, 입력값을 적합(Valid)과 부적합(Invalid)으로 분류한 뒤, 예상되는 결과를 검증하는 방법
◦
동등 분할 (Equivalence Partioning)
▪
정의: 입력값 범위가 정해져 있을 경우, 각 범위의 대표값을 이용하여 테스팅
▪
장점:
•
간단하고 이해하기 쉬움
•
랜덤 테스팅보다 체계적임
◦
경계 값 분석 (Boundary Value Analysis)
▪
정의: 입력 값의 주요 오류 대상인 경계 값을 입력 값으로 테스트 케이스를 작성하여 테스팅
◦
의사결정 테이블 (Decision Table)
▪
정의: 입/출력 값이 True, False로 결정될 수 있는 경우 모든 경우의 수를 확인해볼 수 있는 방법
▪
활용:
•
입력, 출력 값이 Yes, No로 결정될 수 있는 경우
•
적은 수의 조건을 가진 입력 값에 유용함
[화이트박스 테스팅 (White-Box Testing)]
•
정의: 소스 코드를 직접 참조하면서 수행하는 테스팅
•
방법:
◦
문장 커버리지 (Statement Coverage)
▪
프로그램을 구성하는 문장들이 최소한 한 번은 실행될 수 있는 입력 값을 테스트 케이스로 선정함
◦
분기 커버리지 (Branch Coverage)
▪
프로그램에 있는 분기를 최소한 한 번은 실행하게 하는 테스팅 방법
◦
조건 커버리지 (Condition Coverage)
▪
&&, || 등의 조건을 가진 분기문이 전체 조건식의 결과와 관계없이, &&나 || 전후의 각 개별 조건식이 참 한 번, 거짓 한 번을 갖도록 테스트 케이스를 만드는 방법
◦
다중 조건 커버리지 (Multiple Condition Coverage)
▪
조건 커버리지가 각 개별 조건식의 조건을 검사하는 것이라면, 다중 조건 커버리지는 전체 조건식의 모든 경우의 조건을 검사하는 테스트 케이스를 만드는 방법
[기본 경로 테스팅 (Basic Path Testing)]
•
정의:
◦
프로그램의 제어구조를 플로우 그래프(Flow Graph)로 표현하고
◦
순환복잡도(Cyclomatic Complexity)를 통해 독립적인 경로의 수를 찾아 테스트 케이스를 추출하는 기법
•
테스트 케이스 추출 단계:
1.
테스팅 대상의 플로우 그래프를 그린다.
2.
순환복잡도를 계산한다.
•
순환복잡도를 통해 전체 프로그램 내부구조를 시험할 수 있는 독립적인 경로의 수 계산
•
순환복잡도 공식: CC = R의 수 = E- N + 2 = P + 1
3.
독립적인 경로들을 정의한다.
4.
정의된 각 경로의 테스트 케이스를 작성한다.
“50대의 추교현이 20대의 추교현에게 감사할 수 있도록 하루하루 최선을 다해 살고 있습니다.”
The End.