

[목차]
Knative Serving
쿠버네티스(Kubernetes)는 컨테이너 오케스트레이션의 표준이지만, 개발자에게는 여전히 진입 장벽이 높다. 단순히 애플리케이션 배포를 위해서라도 Deployment, Service, Ingress 등의 리소스를 각각 정의하고 관리해야 하기 때문이다.
Knative는 이러한 복잡성을 추상화하여, 개발자가 인프라 관리보다 핵심 로직의 코드 자체에 집중할 수 있도록 돕는 서버리스 오픈소스 플랫폼이다.
Knative는 크게 Serving과 Eventing으로 구성된다. Serving은 애플리케이션의 배포, 네트워킹, 그리고 오토스케일링(Autoscaling)을 담당하는 컴포넌트이다. Eventing은 이기종 시스템 간의 이벤트 연결과 전송을 담당하는 컴포넌트이다.
이번 글에서는 Knative Serving에 대해 설명할 예정이다.
1. Knative Serving의 4가지 핵심 리소스
Knative Serving은 애플리케이션을 관리하기 위해 4가지 핵심 Custom Resource Definition(CRD)을 제공한다. 이들은 계층적인 의존 관계를 가지며, 개발자가 원하는 상태(Desired State)를 실제 클러스터 상태로 구현한다.
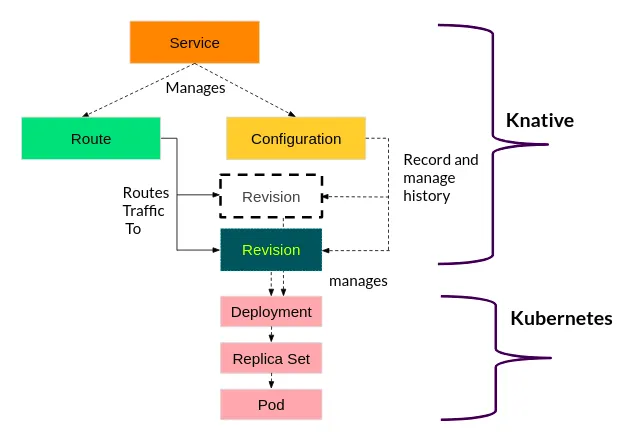
1) Service (서비스)
Knative Service는 전체 애플리케이션의 라이프사이클을 관리하는 최상위 리소스이다. 개발자는 복잡하게 하위 리소스를 개별적으로 관리할 필요 없이, Service 리소스 하나만 정의하면 Knative가 자동으로 하위 리소스의 라이프사이클을 관리한다. 우리가 흔히 아는 쿠버네티스의 Service(네트워크 추상화 리소스)와는 다르다.
2) Configuration (설정)
Configuration은 애플리케이션이 어떤 상태(Desired State)여야 하는지 정의하는 리소스이다. 컨테이너 이미지, 환경 변수, 리소스 제한 등이 여기에 포함된다. 가장 중요한 특징은 코드와 설정을 분리하여 관리한다는 점이다. Configuration이 수정될 때마다(예: 이미지 태그 변경, 환경 변수 수정 등) Knative는 새로운 Revision을 생성한다.
3) Revision (리비전)
Revision은 특정 시점의 Configuration에 대한 불변(Immutable) 스냅샷이다. 코드가 수정되거나 설정이 바뀌면 새로운 Revision이 생성된다. 가장 중요한 특징은 변경 불가능(Immutable)하다는 점이다. 한번 생성된 Revision은 수정할 수 없으며, 이를 통해 언제든 과거 버전으로 롤백하거나, 여러 버전(Canary 배포 등)을 동시에 실행할 수 있다. 마치 Git의 커밋처럼 시스템의 변경 이력을 관리하는 단위로 보면 된다.
4) Route (라우트)
Route는 들어오는 네트워크 트래픽을 하나 이상의 Revision으로 매핑하는 규칙을 정의한다.
단순히 최신 버전(@latest)으로 100% 트래픽을 보낼 수도 있지만, A/B 테스트나 점진적 배포(Progressive Delivery)를 위해 v1: 90%, v2: 10%와 같이 정교한 트래픽 분할을 지원한다.
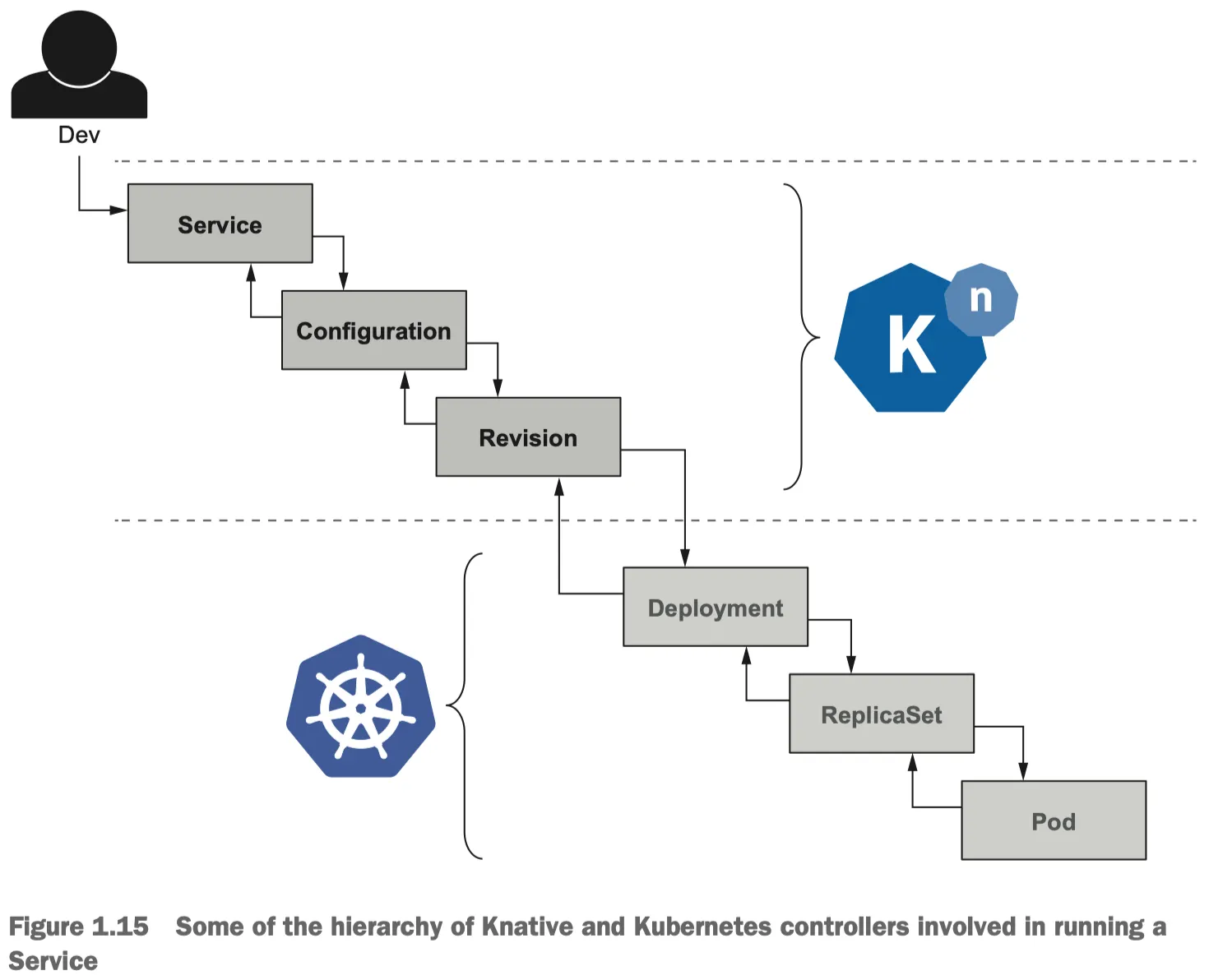
 쿠버네티스 리소스와의 관계
쿠버네티스 리소스와의 관계
Knative는 쿠버네티스 위에 존재하는 추상화 계층이다. 개발자는 상위의 Knative 리소스(Service, Configuration 등)만 다루면 된다. Knative 컨트롤러는 이 의도를 파악하여 하위의 쿠버네티스 리소스들을 자동으로 생성하고 제어한다.
Knative Revision이 생성되면, 실제 워크로드를 실행하기 위해 쿠버네티스의 Deployment 리소스를 생성한다. 이후 쿠버네티스의 기본 동작 방식대로 Deployment는 ReplicaSet을 만들고, 이 ReplicaSet은 실제 컨테이너가 실행되는 Pod를 만든다.
즉, 개발자가 직접 kubectl apply -f deployment.yaml 을 할 필요 없이 Knative Service만 수정하면 자동으로 하위의 리소스인 Deployment가 업데이트되어 Pod가 생성되는 구조이다.
2. Autoscaling: KPA와 Scale-to-Zero의 동작 원리
Knative Serving의 가장 큰 특징은 HTTP 요청 기반의 오토스케일링과 트래픽이 없을 때 리소스를 0으로 줄이는 Scale-to-Zero 기능이다.
KPA (Knative Pod Autoscaler)
쿠버네티스의 HPA(Horizontal Pod Autoscaler)가 주로 CPU/Memory 사용량을 지표로 삼는 반면, Knative의 KPA는 동시 요청 수(Concurrency)를 기준으로 스케일링한다. 이는 처리량(Throughput)이 중요한 웹 서비스에 더 적합한 지표다.
Autoscaling 컴포넌트
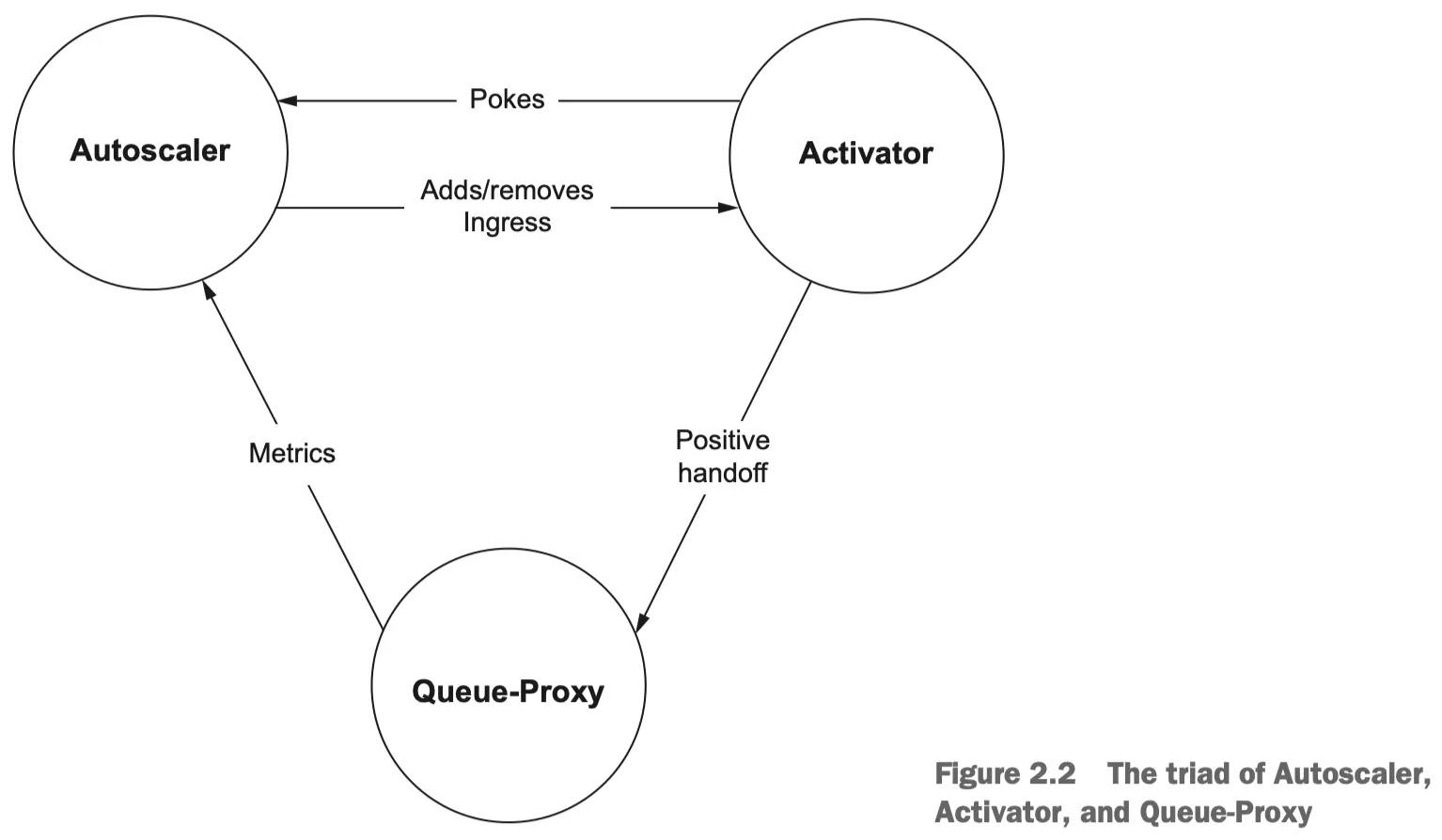
1.
Autoscaler (오토스케일러):
•
역할: 얼마나 많은 파드가 필요한지 계산하고 결정을 내린다.
◦
수집된 메트릭을 기반으로 필요한 파드의 수를 계산하는 제어 루프(Control Loop)이다.
◦
기본적으로 60초(Stable Window) 동안의 평균 트래픽을 기준으로 스케일링을 결정한다.
•
동작:
◦
Queue-Proxy로부터 현재 트래픽 양을 보고받는다.
◦
Activator로부터 “지금 요청이 들어왔으니 깨어나라”는 신호(Poke)를 받는다.
◦
위의 정보를 종합하여 Deployment의 Replicas 수를 0에서 1로, 혹은 1에서 N으로 조절한다.
◦
Adds/removes Ingress:
▪
Pod가 0개일 때: Autoscaler는 트래픽이 Activator를 거쳐가도록 경로를 수정함으로써 요청을 버퍼링할 수 있도록 한다.
▪
Pod가 충분할 때: 굳이 Activator를 거칠 필요가 없으므로, 트래픽이 Pod(Queue-Proxy)로 직접 가도록 경로를 수정하여 성능을 최적화한다. (Activator를 경로에서 제거)
2.
Activator (액티베이터):
•
역할: ‘대기소’ 역할을 하는 로드 밸런서이다.
•
동작:
◦
Cold Start 처리: 현재 실행 중인 파드가 0개일 때, 들어오는 요청을 일시적으로 버퍼링하고 Autoscaler에게 파드 생성을 요청(”Poke”)한다.
◦
트래픽 스로틀링: 파드가 준비될 때까지 요청을 붙잡고 있다가(Buffering), 파드가 준비되면 요청을 전달한다.
◦
Positive handoff:
▪
Activator가 버퍼링하고 있던 요청을, 막 생성되어 준비가 완료된 Pod(Queue-Proxy)에게 넘겨주는 과정
▪
성공적으로 데이터를 인계한다는 의미에서 “Positive”라는 단어를 사용한다.
3.
Queue-Proxy (큐 프록시):
•
역할: 각 애플리케이션 파드 안에 함께 배포되는 사이드카 형태인 경량 프록시이다. (*OpenFaaS에는 Watchdog라는 경량 프록시를 사용한다.)
•
동작:
◦
실제 애플리케이션 컨테이너로 들어가는 모든 네트워크 트래픽은 이 Queue-Proxy를 먼저 거쳐간다.
◦
현재 이 파드가 몇 개의 요청을 동시에 처리하고 있는지(Concurrency)를 측정한다.
◦
이 측정된 데이터를 주기적으로 Autoscaler에게 보고하여 스케일링의 근거를 제공한다.
◦
설정된 동시성 제한(Concurrency Limit)을 초과하는 요청이 들어오면 큐에 대기시켜 애플리케이션 과부하를 방지한다.
Panic Mode
갑작스러운 트래픽 폭증에 대응하기 위해 KPA는 패닉 모드를 지원한다.
짧은 시간(기본 6초, Panic Window) 동안의 평균 트래픽이 기준치(Panic Threshold, 기본 200%)를 초과할 경우 발동한다. 60초 평균을 기다리지 않고 즉시 스케일 아웃(Scale-out)을 수행하는데, 패닉 모드 중에는 스케일 다운(Scale-in)은 수행하지 않는다.
3. Knative Serving 실습 (feat. kn CLI)
kn CLI를 사용하여 위에서 설명한 개념들이 실제 클러스터에서 어떻게 동작하는지 확인해 본다.
1) Service 생성 및 배포
가장 먼저 간단한 Hello World 애플리케이션을 배포한다. 이 명령어 하나로 Service, Configuration, Revision, Route가 모두 생성된다.
# Hello World 서비스 생성
kn service create hello \
--image gcr.io/knative-samples/helloworld-go \
--env TARGET="Knative"
# 생성된 리소스 확인
kn service list
kn revision list
Shell
복사


[참고] 연구실에서 테스트용으로 만들어본 함수들이 많아서 hello 말고도 다른 함수들이 있음
hello-00002와 같은 이름의 첫 번째 Revision이 생성되고, 트래픽의 100%가 이곳으로 라우팅된다.
2) Configuration 변경 및 Revision 업데이트
환경 변수를 변경하여 Configuration을 업데이트한다. 이는 즉시 새로운 Revision 생성을 트리거한다.
# 환경 변수 수정 (Configuration 변경)
kn service update hello --env TARGET="World"
# Revision 목록 확인
kn revision list
Shell
복사

hello-00003과 같은 새로운 Revision이 생성되고, 최신 Revision(@latest)으로 트래픽이 자동 전환된다. 기존 Revision은 삭제되지 않고 남아있다.
3) Traffic Splitting (Route 제어)
두 개의 Revision에 트래픽을 40:60으로 분산시켜 본다.
# Revision 이름 확인 후 트래픽 분할 적용
kn service update hello \
--traffic hello-00002=40 \
--traffic hello-00003=60
# 트래픽 분할 확인
kn route describe hello
kn revision list
Shell
복사
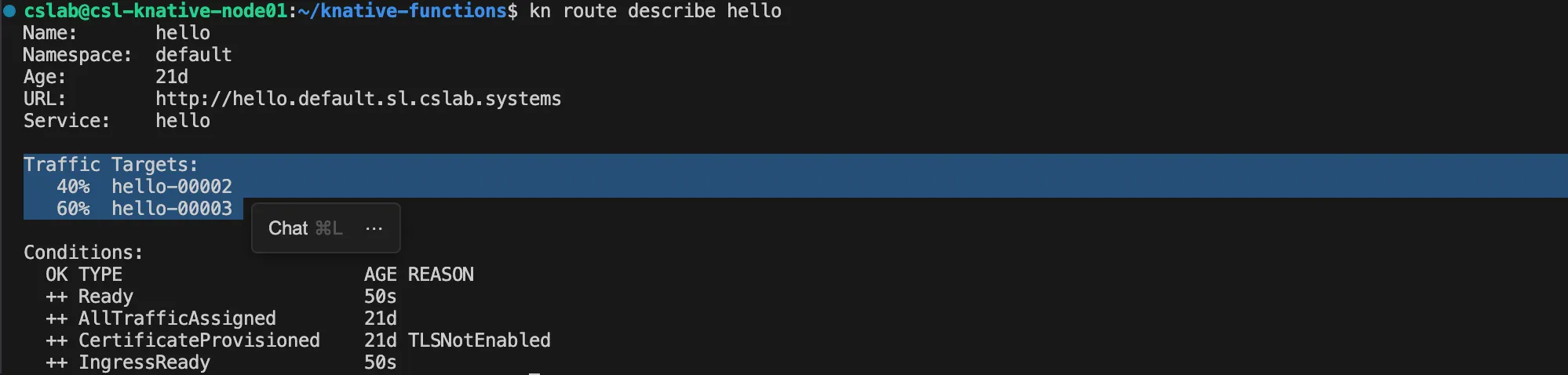

curl -sL http://hello.default.sl.cslab.systems # 실제 hello 함수의 URL
Shell
복사
-sL:
•
s: 진행 상태바(progress bar)를 숨깁니다 (Silent).
•
L: 리다이렉트가 있으면 따라갑니다 (Follow redirects).
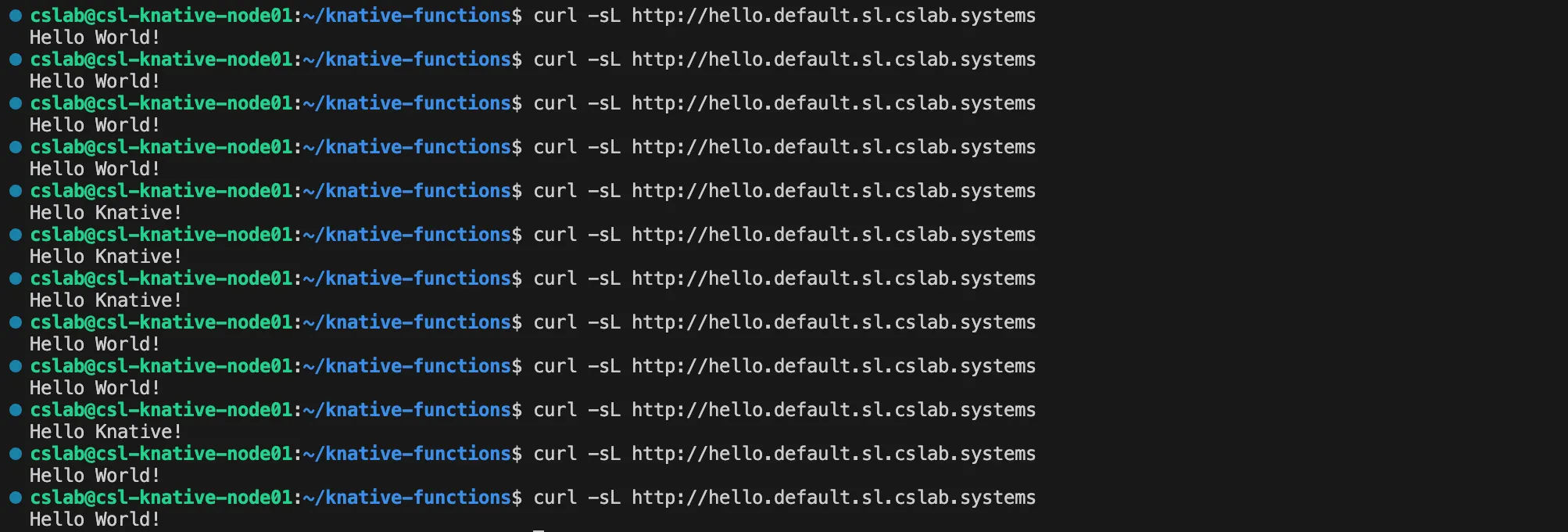
curl 명령어로 해당 서비스 URL을 여러 번 호출하면 “Hello Knative”와 “Hello World”가 번갈아가면서 응답하는 것을 확인할 수 있다.
Knative Eventing
클라우드 네이티브 환경이 발전함에 따라 마이크로서비스 아키텍처는 단순한 서비스 분리를 넘어 서비스 간의 결합도를 낮추고 유연성을 확보하는 방향으로 나아가고 있다.
쿠버네티스 위에서 서버리스 워크로드를 관리하는 Knative는 크게 Serving과 Eventing으로 나뉜다. Serving은 HTTP 요청에 대한 응답과 오토스케일링(Request/Reply)을 담당한다면, Knative Eventing은 시스템 내 이질적인 컴포넌트들을 ‘이벤트’로 연결하고 그 흐름을 관리하는 데 초점을 맞춘다.
이번 글에서는 Knative Eventing의 구조와 데이터 표준인 CloudEvents, 그리고 이를 구현하는 핵심 컴포넌트인 Source, Broker, Trigger, Flow에 대해 설명하고자 한다.
1. CloudEvents: 이벤트 표준
이벤트 기반 시스템에서 가장 중요한 문제는 서로 다른 시스템 간에 이벤트를 이해할 수 있는 공통의 포맷을 정의하는 것이다. Knative Eventing은 CNCF(Cloud Native Computing Foundation) 재단에서 정의한 CloudEvents 명세를 데이터 전송의 표준 포맷으로 채택하고 있다. 이는 이벤트 생산자(Producer)와 소비자(Consumer)가 서로에 대해 알지 못해도 이벤트를 주고받을 수 있게 해준다.
CloudEvents의 구조
CloudEvents는 크게 데이터(Data)와 이를 설명하는 속성(Attributes)으로 구성된다.
•
필수 속성 (Required Attributes):
◦
specversion: CloudEvents 명세의 버전 (예: 1.0)
◦
type: 이벤트의 유형 (예: com.example.order.created - 리버스 도메인 표기법 권장)
◦
source: 이벤트를 발생시킨 논리적 위치 식별자
◦
id: 이벤트를 구별하는 고유 식별자
•
선택 속성 (Optional Attributes):
◦
time: 이벤트 발생 시간
◦
subject: 이벤트 대상
◦
datacontenttype: 데이터 필드의 미디어 타입
전송 모드 (Protocol Bindings)
CloudEvents는 HTTP와 같은 전송 프로토콜을 통해 크게 두 가지 방식으로 매핑된다.
1.
구조화된 모드 (Structured Content Mode): 이벤트의 데이터와 속성을 하나의 JSON 객체로 묶어 HTTP 바디 전체에 담아 전송한다.
2.
바이너리 모드 (Binary Content Mode): 이벤트 속성(메타데이터)은 HTTP 헤더(예: ce-type, ce-source)에 담고, 실제 데이터는 HTTP 바디에 담아 전송한다.
2. Knative Eventing 아키텍처와 Duck Typing
Knative Eventing의 아키텍처는 크게 메시징(Messaging), 이벤트(Eventing), 소스(Sources), 흐름(Flows)의 네 가지 범주로 나눌 수 있다.
•
Messaging Layer (Channels & Subscriptions): 이벤트를 실제로 이동시키는 역할을 한다. Kafka, RabbitMQ, NATS와 같은 메시지 큐 시스템을 추상화하여 일관된 인터페이스를 제공한다.
•
Eventing Layer (Brokers & Triggers): 개발자가 주로 상호작용하는 추상화 계층이다. 이벤트를 수신하고 필터링하여 적절한 곳으로 라우팅하는 논리적인 흐름을 정의한다.
Duck Typing의 활용
Knative가 쿠버네티스 생태계에서 유연한 확장성을 가질 수 있는 메커니즘 중 하나는 바로 “Duck Typing(덕 타이핑)”이다. 동적 타입 언어에서 주로 사용되는 이 개념이 정적 타입 언어인 Go 기반의 Knative에 어떻게 적용되는지 살펴보자. Duck Typing은 “만약 어떤 새가 오리처럼 걷고 오리처럼 꽥꽥 운다면, 그 새를 오리라고 부를 수 있다”는 개념에서 유래했다.
•
정적 타이핑 (예: Java): 변수의 타입이 생성 시점에 결정된다. 컴파일 타임에 버그를 잡기 좋지만, 모든 타입을 미리 정의해야 하므로 유연성이 떨어질 수 있다.
•
동적 타이핑 (예: Ruby): 객체의 타입이 런타임에 결정된다. 유연하지만, 런타임 오류 위험이 있다.
Go 언어는 정적 타이핑 언어이지만, 독특한 인터페이스 시스템을 갖고 있다. Java처럼 implements 키워드를 명시할 필요 없이, 특정 메서드 집합을 구현하기만 하면 해당 인터페이스로 간주한다.
하지만 Go에는 명확한 한계가 있다. Go는 메서드(Interface)와 데이터(Struct)를 엄격하게 구분한다.
•
Interface: 메서드의 집합을 정의. 유연한 구현이 가능.
•
Struct: 메시지 필드를 정의. 한번 정의되면 고정적이며, 다른 타입으로 대체하기 어려움.
문제는 데이터 모델의 일부만 공유하고 싶은 경우에 발생한다는 점이다. 예를 들어, 서로 다른 리소스들이 url이라는 데이터필드를 가지고 있다면, 이들을 하나의 공통 타입으로 처리하고 싶을 때 Go의 기본 문법으로는 한계가 있다.
이를 해결하기 위해 Knative의 Duck Typing은 인터페이스처럼 동작하는 데이터 필드를 정의하는 개념이다. 즉, 특정 리소스가 보장된 데이터 필드(Guaranteed data fields)를 갖고 있다면, 그 리소스의 구체적인 타입이 무엇이든 상관없이 공통된 기능을 수행할 수 있게 만든다.
[예시(1): Addressable]
Knative에는 Addressable 이라는 개념이 있다. 이는 “주소(URL)를 갖고 있는 모든 것”을 의미한다: Knative Service, Kubernets Service, Channel, Broker
이 리소스들은 모두 서로 다른 구체적인 타입(Struct)이지만, 모두 status.address.url이라는 공통된 데이터 필드를 갖고 있다. Knative는 이 공통 필드가 존재한다는 것만으로 이들을 모두 Addressable이라는 Duck Type으로 취급하여 이벤트를 전송한다.
[예시(2): IceCream]
책 “Knative in Action”에서는 IceCream과 Sundae의 예시를 들었다.
•
IceCream: 맛(flavor)과 스쿱 수(scoops)를 가진다.
•
Sundae: Icecream의 필드인 flavor와 scoops를 포함하면서 토핑(topping)을 추가로 가진다.
Knative의 Duck Typing을 사용하면, 시스템은 Sundae가 IceCream의 데이터 구조를 포함하고 있다는 사실만으로 나머지 필드인 토핑(topping) 정보는 무시하고 공통된 데이터에만 집중하여 Sundae를 Icecream처럼 처리할 수 있게 된다.
이를 통해 개발자는 새로운 리소스 타입을 정의할 때 기존 시스템을 수정하지 않고도, 단지 약속된 데이터 필드만 포함시킴으로써 Knative에 즉시 통합될 수 있도록 확장성을 높이는 메커니즘이다.
1) Broker and Trigger: 이벤트 라우팅 및 필터링
복잡한 이벤트 기반 시스템에서 생산자와 소비자를 분리하기 위해 Broker와 Trigger 모델을 사용한다.
[Broker]
Broker는 이벤트의 중앙 허브(Hub) 역할을 하며, Source로부터 유입되는 모든 이벤트를 수신하여 버퍼링한다. 기본적으로 In-Memory Channel을 사용하지만, 프로덕션 환경에서는 Kafka 등을 사용할 수도 있다.
[Trigger]
Trigger는 Broker에 들어온 이벤트 중 특정 조건에 맞는 이벤트만 선별(Filter)하여 구독(Subscribe)하는 규칙이다. Trigger는 필터 조건과 이벤트를 전달받을 Subscriber 정보를 포함한다.
[Filtering 메커니즘]
Trigger의 필터링은 CloudEvents의 속성에 대해서만 동작하며, 데이터 페이로드(Body)에 대한 필터링은 지원하지 않는다.
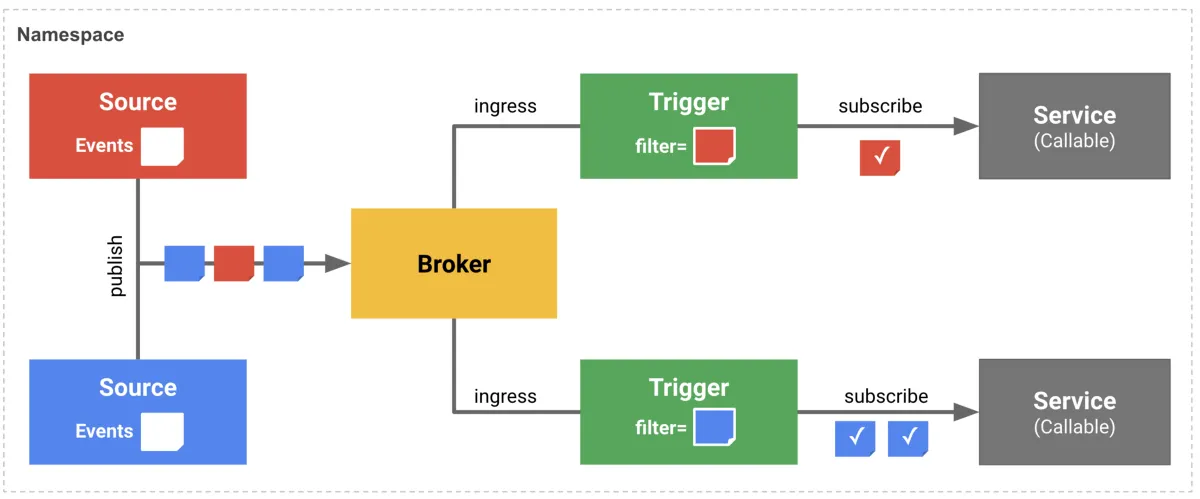
[Broker & Trigger 아키텍처]
1.
이벤트 수집 (Publish): 왼쪽의 Source들은 서로 다른 유형의 이벤트(빨간색, 파란색)를 생성하여 중앙의 Broker로 전송(publish)한다. 이때, Source는 누가 이 이벤트를 소비할지 전혀 알 필요가 없다. 단지 Broker라는 우체통에 이벤트를 넣기만 하면 된다.
2.
이벤트 버퍼링 및 평가 (Ingress): Broker는 유입된 모든 이벤트를 수신하고 버퍼링한다. 그리고 등록된 Trigger들의 조건(Filter)을 확인하여 어떤 이벤트가 어떤 서비스로 전달되어야 하는지 평가한다.
3.
필터링 및 구독 (Filter & Subscribe):
•
상단 Trigger: ‘빨간색 이벤트’만 통과시키도록 필터가 설정되어 있다. Broker에 빨간색 이벤트가 도착하면, 이 Trigger가 활성화되어 상단의 Service로 이벤트를 전달한다.
•
하단 Trigger: ‘파란색 이벤트’를 구독하고 있다. 따라서 파란색 이벤트가 감지될 때만 하단의 Service로 라우팅한다.
4.
최종 전달 (Delivery): 결과적으로 각 Service는 자신에게 필요한 특정 이벤트만을 선별적으로 전달받게 된다. 만약 필터 조건에 맞지 않는 이벤트가 들어온다면, 해당 이벤트는 어떤 서비스로도 전달되지 않고 무시된다.
이처럼 Broker와 Trigger를 사용하면 이벤트를 보내는 쪽(Source)과 받는 쪽(Service)이 서로의 존재를 몰라도 되는 강하게 분리된 비동기 구조(Decoupling)를 완성할 수 있다.
2) Sources and Sinks: 이벤트를 가져오는 방법
이벤트의 여정은 Source에서 시작되어 Sink에서 끝난다.
[Source]
Source는 외부 시스템이나 클러스터 내부에서 발생하는 이벤트를 감지하여 CloudEvents 포맷으로 변환하고, 이를 지정된 Sink(목적지)로 전달하는 역할인 Kubernetes Custom Resource이다.
[SinkBinding]
이미 존재하는 애플리케이션을 수정하지 않고도 Source로 만들고 싶다면 SinkBinding을 사용할 수 있다. SinkBinding은 대상 리소스(Subject)에 K_SINK 라는 환경 변수를 주입한다. 애플리케이션은 이 환경 변수에 설정된 URL로 데이터를 보내기만 하면, Knative가 이를 지정된 Sink로 라우팅한다.
3) Flows (Sequence & Parallel)
복잡한 이벤트 처리 로직을 구현하기 위해 Knative는 Sequence와 Parallel이라는 고수준의 흐름(Flow) 리소스를 제공한다.
•
Sequence: 이벤트를 일련의 단계(Step)를 거쳐 순차적으로 처리하는 파이프라인을 구성한다. 예를 들어, Step A → Step B → Step C 와 같이 구성하면, Step A의 출력 이벤트가 Step B의 입력으로, Step B의 출력이 Step C의 입력으로 자동 연결된다.
•
Parallel: 들어온 이벤트를 여러 구독자에게 동시에 전달(Fan-Out)하는 패턴을 구현한다. 각 구독자가 처리를 완료하면 그 결과를 수집하거나, 필터링하여 다음 단계로 넘길 수 있다.
이러한 Flow 리소스를 사용하면 개발자가 직접 Broker와 Trigger를 복잡하게 일일이 연결하지 않고도 선언적으로 이벤트 처리 파이프라인을 구성할 수 있다.
3. Knative Eventing 실습 (feat. kn CLI)
앞서 배운 내용을 바탕으로 실제 클러스터에서 이벤트 파이프라인을 구축해 보자. 우리는 PingSource를 사용해 1분마다 이벤트를 생성하고, 이를 Broker와 Trigger를 통해 CloudEvents Player라는 웹 애플리케이션으로 전달할 것이다.
Step 1. Broker 생성: 이벤트 허브
# Broker 생성
kn broker create default
# 생성된 broker 확인
kn broker list
Shell
복사

이벤트를 수신하고 분배할 메모리 기반(In-Memory) 채널을 사용하는 default Broker를 생성한다.
Step 2. Sink 배포: 이벤트 받을 곳
# Knative Service 생성
kn service create cloudevents-player \
--image kyohyunchoo/cloudevents-player:latest \
--env BROKER_URL=http://broker-ingress.knative-eventing.svc.cluster.local/default/default
# 생성된 서비스 확인
kn service list
Shell
복사
[AS-IS]
처음에는 --image ruromero/cloudevents-player:latest 이미지로 Service를 생성했는데, 구버전이어서 다음과 같이 접근이 안 되는 에러가 발생했다.
[에러] 웹소켓 연결 주소가 HTTPS인 경우를 고려하지 않고 하드코딩 됨 ⇒ 연결 차단
⇒ 원인: ruromero/cloudevents-player 레포지토리 가보니까 최신 버전이 이미지로 배포되지 않았다.
[TO-BE]
따라서, 내가 직접 최신 코드를 로컬로 가져와서 이미지를 빌드하고 Docker Hub에 배포했다.
[해결] 직접 최신 버전 코드를 도커 허브에 이미지로 배포

이벤트를 눈으로 확인할 수 있는 cloudevents-player 서비스를 배포한다. 이 서비스는 들어온 이벤트를 웹 UI에 보여주는 역할을 한다.
Step 3. PingSource 연결: 이벤트 생성기
# Source 생성
kn source ping create test-ping-source \
--schedule "* * * * *" \
--data '{"message": "Hello Knative!"}' \
--sink broker:default
Shell
복사
•
--schedule: Cron 표현식을 사용하여 이벤트 생성 주기를 설정
•
--sink broker:default: 생성된 이벤트를 default Broker로 보낸다. 여기서 Knative의 Duck Typing이 적용되어 Broker를 주소(Addressable)로 인식한다.
# Source 확인
kn source ping list
Shell
복사

Source가 생성되어 Broker(Sink)와 정상적으로 연결되었는지 확인한다.
Step 4. Trigger 설정: 이벤트 라우팅
# Trigger 생성
kn trigger create test-trigger \
--filter type=dev.knative.sources.ping \
--sink ksvc:cloudevents-player
# Trigger 확인
kn trigger list
Shell
복사

Broker로 들어온 이벤트 중 PingSource가 보낸 이벤트만 골라내어 cloudevents-player로 전달하는 Trigger를 생성한다.
Step 5. 최종 결과 확인
모든 컴포넌트의 READY 상태가 True면 파이프라인이 완성된 것이다.
1.
Step 2에서 확인한 cloudevents-player 의 URL을 웹 브라우저에서 연다.
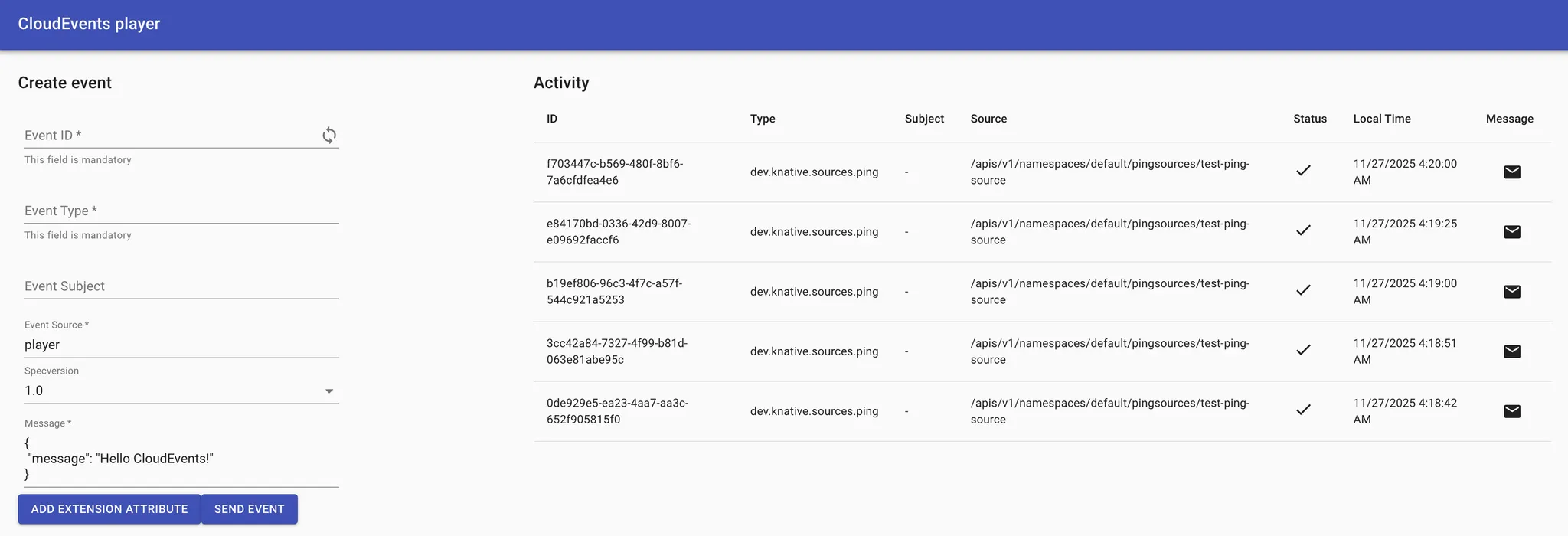
2.
잠시 기다리면 매분마다 새로운 이벤트 카드가 화면에 나타나는 것을 볼 수 있다.
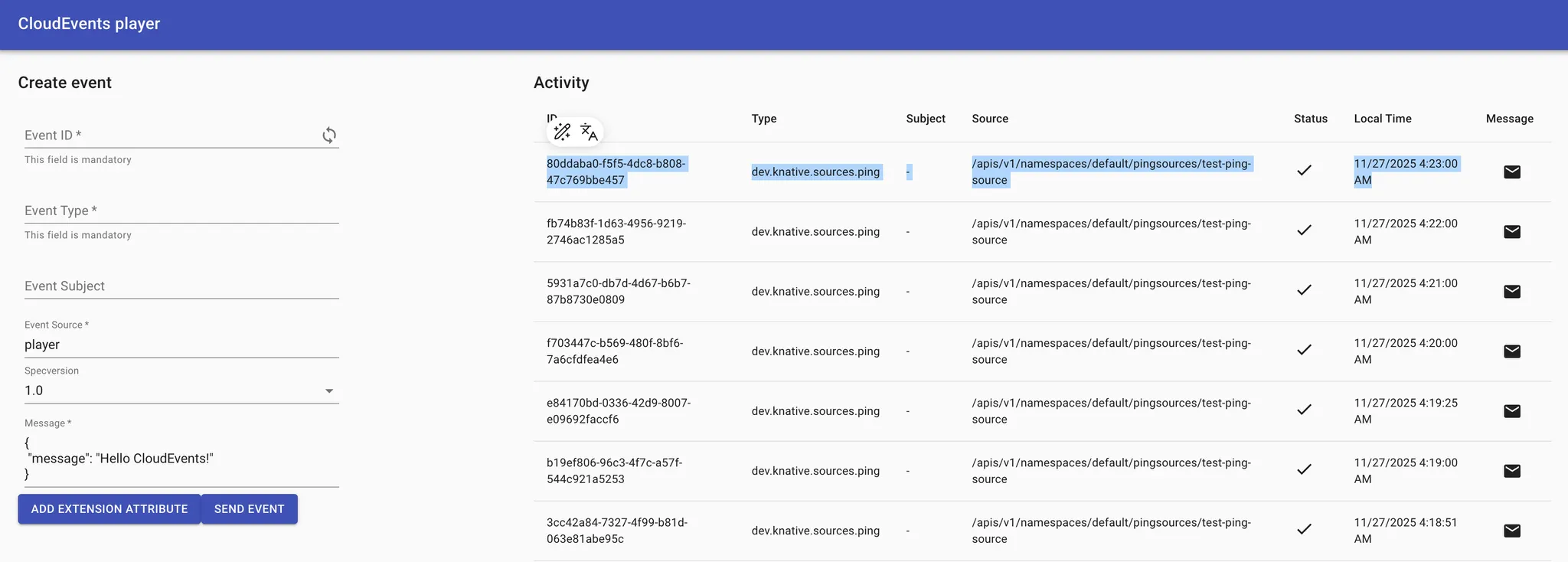
3.
카드 아이콘을 클릭하여 상세 내용을 확인해보자.
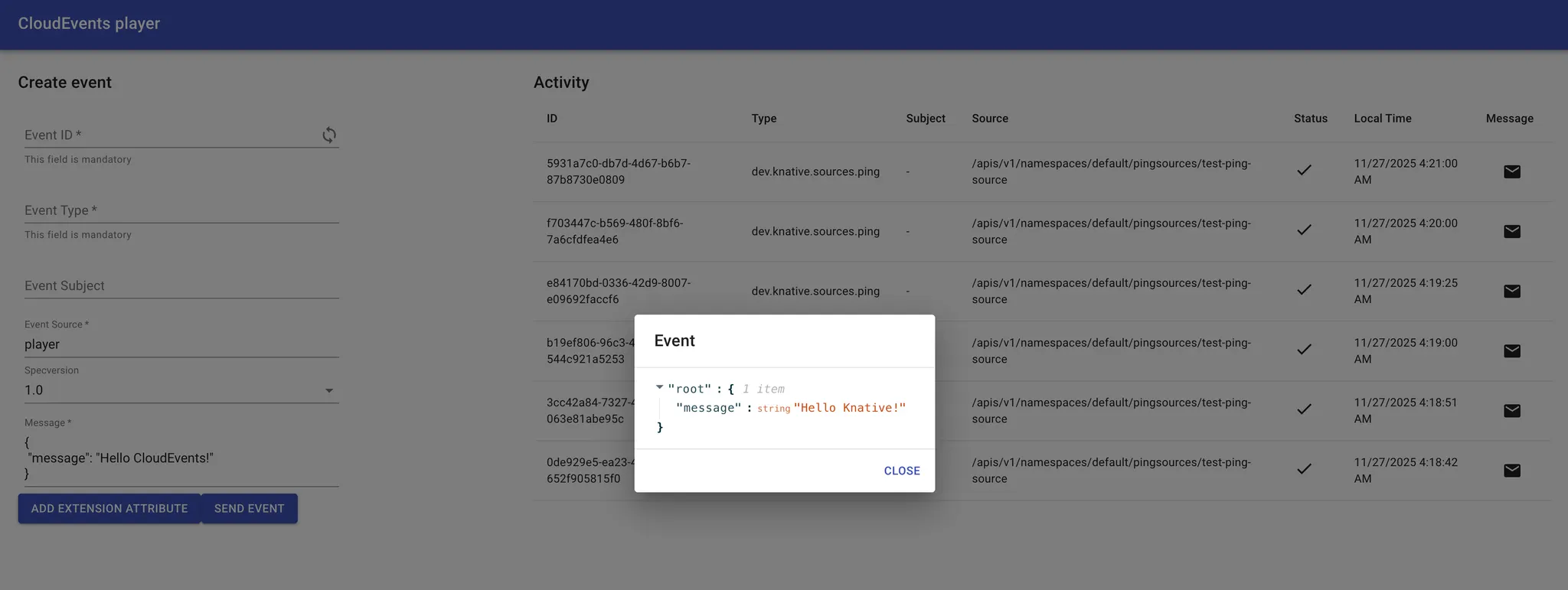
a.
Ce-Type: dev.knative.sources.ping
b.
Data: {"message": "Hello Knative!"}
주기적으로 이벤트(ping)를 Broker에게 보내면, 이벤트가 Sink인 cloudevents-player 서비스로 보내진다.
“50대의 추교현이 20대의 추교현에게 감사할 수 있도록 하루하루 최선을 다해 살고 있습니다.”
The End.