.jpeg&blockId=badfaa9e-f57f-4405-9497-65dc263adb24&width=3600)
 ABOUT ME
ABOUT ME

•
•
Goal: Spreading “Good Influence” around the World through “Technology” (기술을 통해 세상에 선한 영향력을 퍼뜨리자)


MAJOR SUBJECTS
SUBJECT | GRADE |
[Bachelor’s course] | |
Algorithm (알고리즘) | A+ |
Data Structure (자료구조) | A+ |
Operating System (운영체제) | A+ |
Computer Architecture (컴퓨터구조) | A0 |
Computer Network (컴퓨터통신) | A0 |
Database Design (데이터베이스 설계) | A+ |
Deep Learning (이미지 및 자연어 처리를 위한 딥러닝) | A+ |
Object-Oriented Programming (객체지향프로그래밍) | A+ |
SUBJECT | GRADE |
[Master’s course] | |
Statistical Machine Learning (통계기반 머신러닝) | A+ |
Advanced Natural Language Processing (고급자연어처리) | A+ |
Advanced Operating System (고급운영체제) | A0 |
Advanced Distributed and Parallel Processing (고급분산및병렬처리) | A+ |
Advanced Computer Security (고급컴퓨터보안) | A0 |
Advanced Computer Network (고급컴퓨터네트워크) | A+ |
Software Engineering Methodology (소프트웨어 공학론) | A+ |






BLOG
🔥 Featured 🔥

벌써 2026년의 절반이 지나갔습니다
26년 2분기는 딱 한 가지에 몰두했던 분기였습니다. 온디바이스 AI라는 새로운 분야에 제대로 뛰어들기 위해서 관련 기본 지식을 쌓고 여러 논문들을 읽으며 논문 아이디어를 찾아내고자 최선을 다했습니다. 그래서 이번 회고는 조금 담백하지만, 개인적으로는 가장 밀도 높았던 분기가 아닐까 싶습니다.
[26.04] 클라우드 연구에서 온디바이스 연구로 전환
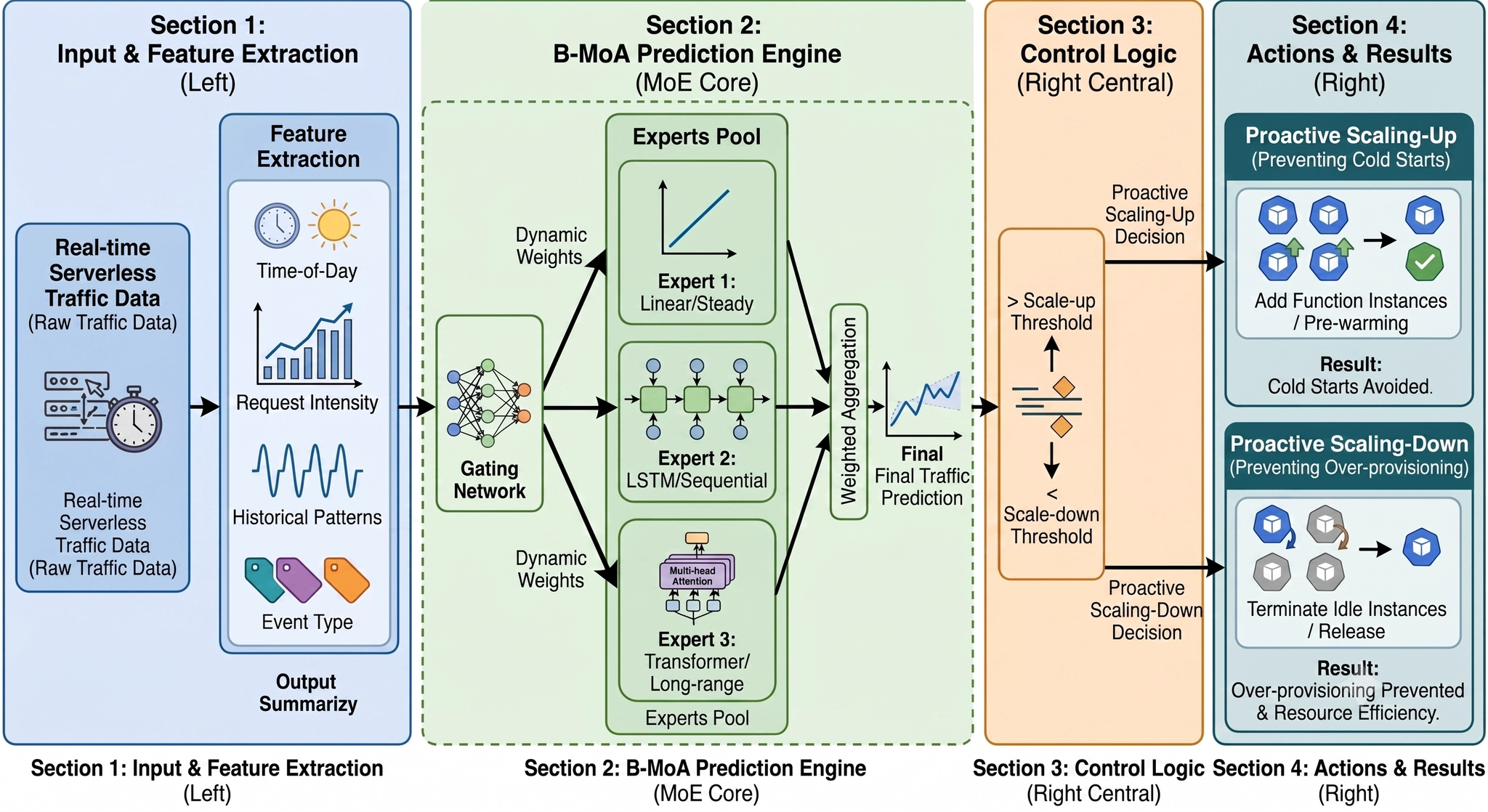
B-MoA Architecture by Gemini
지난 1분기 회고에서 말씀드렸듯이, HPDC에 투고했던 B-MoA 논문이 아쉽게 Reject를 받았습니다 . 리뷰어 분들의 피드백을 반영하면 더 좋은 논문이 되겠다는 생각에 4월 초에는 B-MoA를 다시 붙잡고 재설계 및 실험을 진행했습니다.
. 리뷰어 분들의 피드백을 반영하면 더 좋은 논문이 되겠다는 생각에 4월 초에는 B-MoA를 다시 붙잡고 재설계 및 실험을 진행했습니다.B-MoA는 서버리스 컴퓨팅의 Burst한 트래픽을 MoE(Mixture-of-Experts) 구조로 예측하여, 함수 인스턴스를 미리 띄워 Cold Start를 줄이거나 반대로 미리 꺼서 Over-provisioning을 막는 연구입니다.
그런데 실험을 여러 번 다시 진행해 보니, 애초에 Burst한 트래픽을 예측하는 것 자체가 너무 어려운 문제였고, 이것이 아이디어의 근본적인 한계라는 결론에 이르렀습니다.
26년 2분기 회고 & 계획
온디바이스 AI 연구로 전환, 여러 편의 KV Cache 양자화 및 Attention 커널 논문 정독, 연구 아이디어 확정
2026/07/07

이 글은 FlashAttention-2(Tri Dao, ICLR ‘23)와 NVIDIA A100 Tensor Core GPU Architecture를 바탕으로, 커널 launch부터 Tensor Core 연산까지의 전체 실행 경로를 하나의 시나리오로 정리한 글이다.
BitDecoding(HPCA ‘26) 논문을 읽다가 아래 Fig 3을 이해하지 못해서 Tensor Core가 어떤 식으로 동작하는지 공부하다가 정리한 글이다. Tensor Core가 어떤 식으로 동작하는지 알기 위해서 GPU가 어떻게 구성되어 있으며, 행렬을 어떤 식으로 나눠서 연산하는지 알아야만 했다. 시간은 조금 걸렸지만, BitDecoding의 Figure 3을 확실히 이해할 수 있었다.
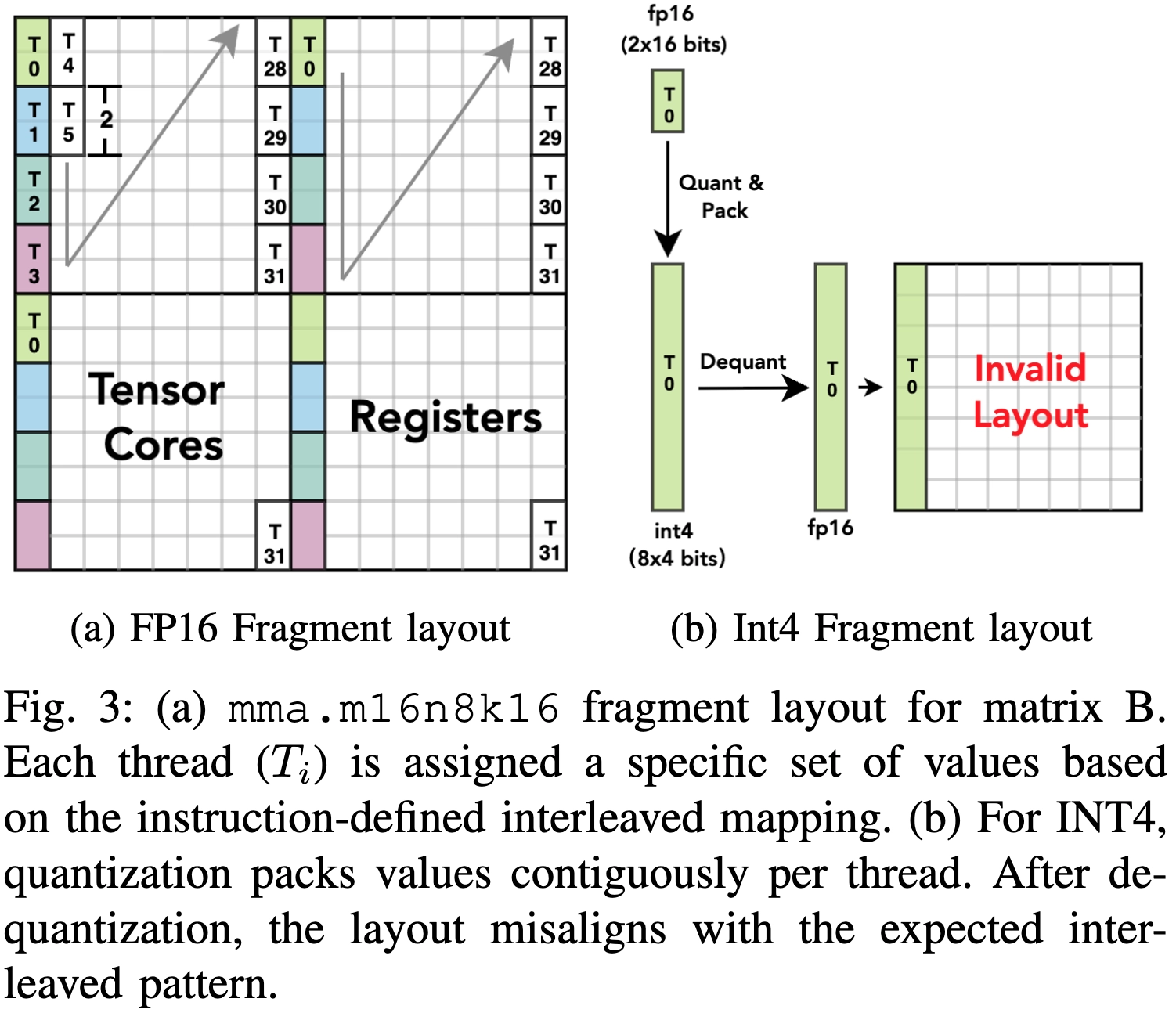
kernel<<<grid, block>>>() 한 줄을 호출한 그 순간부터, GPU 안에서 Thread Block이 SM에 배정되고, Warp가 작업을 나누고, Tensor Core가 행렬을 곱하기까지의 전체 경로를 Top-Down으로 정리했다. Attention Kernel은 FlashAttention-2를 기준으로, 256x128 크기의 Q⋅K⋅V가 어떻게 Tile로 쪼개져 SM과 Warp, 그리고 Thread의 Register까지 흘러내려가는지를 숫자 예시와 함께 설명했다.
시작하기 전
추상적인 설명을 피하기 위해 처음부터 끝까지 하나의 구체적인 시나리오를 설정했고, 하드웨어는 GPU A100을 기준으로 한다.
항목 | 값 |
Q, K, V | 각 256×128 (N=256 시퀀스, d=128 head dim) |
타일 크기 | 128×128 (Br=128, Bc=128) |
Q 타일 수 (Tr) | 256 / 128 = 2 |
K·V 타일 수 (Tc) | 256 / 128 = 2 |
MMA 명령 | m16n8k16 (FP16 입력, FP32 누적) |
GPU에서 Attention은 실제로 어떻게 실행되는가 - 커널 Launch부터 Tensor Core까지 (Feat. FlashAttention-2)
2026/06/12

현재(26년 5월 기준) 필자는 대학원 컴퓨터공학과 석사과정 3차 학기이며, “온-디바이스 환경에서 LLM을 추론시킬 때 메모리를 최대한 적게 쓰면서 성능이 유지되는 방향”으로 연구 아이디어를 찾아가는 중이다. 구체적으로는 KV Cache를 양자화(압축)하는 쪽으로 연구 방향을 잡았으며, 이 글은 Weight(가중치) 양자화 방법 중 뿌리에 가까운 GPTQ를 제대로 이해하고자 약 1주일에 걸쳐서 읽고 정리한 글이다.
1. Introduction
GPT-3-175B는 FP16 기준으로 파라미터만 326GB를 차지한다. 이런 거대 모델을 단일 GPU에서 돌릴 수 있게 만드는 핵심 기술이 양자화(Quantization)다.
이 글에서는 ICLR 2023에 발표된 GPTQ 논문을 정리한다. GPTQ는 175B 파라미터 모델을 단일 NVIDIA A100 GPU에서 약 4시간 만에 3~4비트로 양자화하면서, FP16 baseline 대비 거의 무시할 수 있는 정확도 손실만 발생시킨다.
GPTQ를 이해하려면 그 전신인 OBQ(Optimal Brain Quantization)를 먼저 알아야 한다. GPTQ는 OBQ의 핵심 아이디어를 유지하면서 세 가지 결정적인 개선을 통해 대규모 모델 양자화를 가능하게 만든 알고리즘이기 때문이다.
2. Background
[논문 리뷰] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers (ICLR ‘23)
2026/05/13

필자는 현재(26년 4월) 온디바이스(On-device) 환경에서 LLM 추론 효율을 극대화하기 위한 시스템 최적화 연구를 수행하고 있다. 특히 제한된 메모리 자원 내에서 최적의 추론 성능을 확보하는 것을 핵심 목표로 삼고 있다.
최근 LLM의 컨텍스트 길이가 계속해서 확장됨에 따라 KV 캐시가 점유하는 메모리 비중이 시스템의 주요 병목으로 작용하고 있음을 알게 되었다. 이를 해결하기 위해 ‘KV 캐시 양자화(Quantization)’를 세부 연구 방향으로 설정하였다.
이 글은 해당 분야의 랜드마크 논문인 ICML 2024에 올라온 논문 KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache를 정리한 글이며, 필자의 생각이 포함되어 있다.
1. Background
1.1 Quantization 수학적 정의

Fig 1. Quantization(1)
[논문 리뷰] KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache (ICML’24)
2026/04/26

벌써 2026년의 4분의 1이 지나갔습니다. 26년 1분기에는 베트남 하노이에서 학회 참가 및 발표도 하였고 세 번의 시험 끝에 RHCSA 자격증을 취득했습니다. 그리고 연구 방향을 Serverless Computing에서 On-Device AI 시스템 쪽으로 전환했습니다.
[26.01] ICOIN 2026 학회 참가 및 발표 at 베트남
연구실 구성원들과 함께 ICOIN 2026(International Conference on Information Networking) 학회 참석을 위해 2026년 1월 초에 베트남 하노이로 갔습니다.
정확히 7년 전인 2019년 1월, 배낭 하나 메고 남자 6명이서 떠났던 동남아 일주(싱가포르 → 말레이시아 → 태국 → 라오스 → 베트남)의 마지막 여행지가 바로 베트남 하노이였습니다. 당시 기계공학을 전공하던 20대 초반의 제가, 7년 뒤 전공을 완전히 바꿔 컴퓨터공학 대학원생이 되어 하노이에 학회 발표를 하러 오게 될 줄은 전혀 상상하지 못했습니다. 시간이 참 빠르다는 생각과 함께, 매 순간을 더 밀도 있게 살아가야겠다는 다짐을 하게 되었습니다.
학회에서의 영어 발표는 잘 마무리했습니다. 작년 여름 PlatCon 때보다는 확실히 여유가 생겼지만, 여전히 제 생각을 자유롭고 유창하게 표현하는 역량은 부족하다고 느꼈습니다. 연구가 끝이 없듯, 영어 또한 꾸준히 갈고닦아야 할 부분임을 다시 한 번 깨달았습니다.
26년 1분기 회고 & 계획
RHCSA 자격증 취득, On-Device AI 시스템 쪽으로 연구 방향 전환, 논문 Reject
2026/04/09

1. KV Cache란 무엇인가
KV Cache를 이해하려면, 먼저 Transformer의 Self-Attention 연산을 이해해야 한다.
Transformer에서 각 토큰은 세 가지 벡터로 변환된다: Query(Q), Key(K), Value(V). Attention 연산은 Q와 K의 내적으로 각 토큰 간의 관련도(attention score)를 계산하고, 이 score로 V를 가중합하여 최종 출력을 만든다. 수식으로 표현하면 다음과 같다:
Attention(Q,K,V)=softmax(dkQKT)V
LLM은 토큰을 하나씩 순차적으로 생성하는데, 이를 autoregressive하게 생성한다고 한다. 새로운 토큰을 생성할 때마다 이전에 생성된 모든 토큰의 K와 V가 다시 필요하다. 예를 들어, 100번째 토큰을 생성하려면 1~99번째 토큰 전부의 K, V와 attention 연산을 수행해야 한다.
Q. 왜 새로운 토큰을 생성할 때마다 이전에 생성된 모든 토큰의 K와 V가 다시 필요할까?
“이전에 생성된 일부 토큰만 참고하면 안 되나?”라고 생각할 수 있지만, 문제는 어떤 토큰이 중요한지를 알기 위해서는 모든 토큰과 비교를 끝내야 한다는 점이다.
예를 들어 “나는 3년 전에 파리에서 먹었던 크루아상이 그립다. 그래서 오늘은 “이라는 문장에서 다음 토큰을 생성한다고 하자. “빵집”이라는 토큰을 생성하려면 앞쪽에 있는 “파리”, “크루아상” 같은 토큰이 핵심이다. 바로 직전의 “오늘은”만으로는 맥락을 파악할 수가 없다.
어떤 토큰이 중요한지는 문장의 의미에 따라 매번 달라진다. 때로는 바로 직전 토큰이, 때로는 수천 토큰 전의 토큰이 결정적일 수 있다. 이것을 사전에 알 수 없기 때문에, Attention은 원칙적으로 모든 이전 토큰의 K와 score를 계산하고, 모든 이전 토큰의 V를 가중합에 포함시켜야 한다.
KV Cache에 대해 알아보자 (Feat. Attention)
2026/04/08

이 글은 NeurIPS 2024에 올라온 논문 SGLang: Efficient Execution of Structured Language Model Programs를 정리한 글이다.
1. Introduction
1.1 해결하려는 문제: “왜 LLM Program을 위한 시스템이 필요한가”
LLM의 활용 양상이 단순한 채팅에서 multi-call, control flow가 결합된 프로그램적 사용으로 빠르게 전환되고 있다. ReAct agent, Tree-of-Thought (ToT), Branch-Solve-Merge 등 대부분의 프롬프팅 기법은 다음 두 가지 공통 속성을 가진다.
•
다수의 LLM 호출이 control flow와 엮여 있음: 한 task를 풀기 위해 여러 generation call을 chaining
•
구조화된 입출력: JSON Schema 등 외부 시스템과 통합되기 위한 structured I/O 필요
[논문 리뷰] SGLang: Efficient Execution of
Structured Language Model Programs (NeurIPS’24)
2026/04/07

저희 컴퓨터시스템 연구실에서는 Linux를 능숙하게 다루는 것이 중요하여 교수님께서 RHCSA(Red Hat Certified System Administrator)를 취득하도록 연구실 차원에서 지원해 줍니다.
문제는 대학원 연구와 병행하다 보니 시간을 내서 공부하기가 쉽지 않았고 결국 세 번째 시도 끝에 자격증을 취득하게 되었습니다. 첫 번째: 절대적인 공부량 부족, 두 번째: 모든 문제를 잘 풀었음에도 네트워크 설정 오류로 인해 채점되지 않음, 세 번째: 다행히 합격…!
세 번의 시험 모두 기출문제(덤프)에서 크게 벗어나지 않았습니다. 세부적인 값은 매번 달라지지만 문제 유형 자체는 거의 동일한 것 같습니다. 그렇기에 기출문제 위주로 공부하는 것이 가장 효율적인 방법입니다.
이 글을 보시는 분들은 꼭 한 번에 합격하셨으면 좋겠습니다

세 번째 시험 성적 : 합격
기출문제 정리

RHCSA v10 합격 후기 및 기출문제 정리 (feat. 네트워크 설정 주의)
2026/03/31

SGLang이 무엇인가
SGLang(Structured Generation Language for LLMs)은 복잡한 LLM 프로그램(다중 생성 호출, Prompting 기법, 제어 흐름, 구조화된 입출력)을 효율적으로 실행하기 위한 시스템 및 LLM 서빙 프레임워크이다.
자세한 내용은 SGLang 논문을 리뷰한 글에 정리해 두었다.


SGLang 설치 가이드 (Window 편)
LLM 서빙 프레임워크인 SGLang 설치 및 실습
2026/03/16

제 인생의 소중한 순간들을 기록하는 회고록입니다.
대학원 석사과정을 시작하며, 정신 없이 흘러간 2025년의 경험과 생각을 정리하고자 글을 적습니다.
BYE 2025
2025년은 대학원 석사과정을 시작한 해였습니다.
석사 1년 차의 가장 큰 목표는 ‘결과와 상관없이 해외 유명한 학회에 1저자로 논문 투고하기’였습니다. 그리고 지난 2월 초, 분산 시스템 분야의 권위 있는 학회인 HPDC에 “B-MoA: A Robust and Proactive Serverless Autoscaling System for Bursty Workloads using Mixture-of-Experts” 논문을 1저자로 제출하여 그 목표를 달성했습니다.
정신없이 흘러간 1년을 되돌아보니, 치열했던 만큼 남은 것도 많은 한 해였습니다. 지난 1년간의 경험과 배움을 기록한 이 회고 글이 누군가에게 시행착오를 줄여 주는 유용한 가이드라인이 되기를 바라는 마음으로 적었습니다. 재밌게 읽어 주시면 감사하겠습니다!
2025년에 발표한 횟수는? 4회
2025년에 작성한 블로그 글 개수는? 14개
BYE 2025 & HELLO 2026
학부 졸업 및 대학원 석사과정 시작, 1저자로 논문 투고, 셰어하우스 사업 마무리, 여러 학회 참석 및 발표
2026/02/12

[목차]
Knative Serving
쿠버네티스(Kubernetes)는 컨테이너 오케스트레이션의 표준이지만, 개발자에게는 여전히 진입 장벽이 높다. 단순히 애플리케이션 배포를 위해서라도 Deployment, Service, Ingress 등의 리소스를 각각 정의하고 관리해야 하기 때문이다.
Knative는 이러한 복잡성을 추상화하여, 개발자가 인프라 관리보다 핵심 로직의 코드 자체에 집중할 수 있도록 돕는 서버리스 오픈소스 플랫폼이다.
Knative는 크게 Serving과 Eventing으로 구성된다. Serving은 애플리케이션의 배포, 네트워킹, 그리고 오토스케일링(Autoscaling)을 담당하는 컴포넌트이다. Eventing은 이기종 시스템 간의 이벤트 연결과 전송을 담당하는 컴포넌트이다.
이번 글에서는 Knative Serving에 대해 설명할 예정이다.
1. Knative Serving의 4가지 핵심 리소스
Knative Serving/Eventing: 쿠버네티스 기반 서버리스 오픈소스 플랫폼 (feat. 실습)
2025/11/24

2025년 2학기 대학원 과목인 “고급컴퓨터보안” 수업 내용을 정리한 글입니다.
[Week 1] Introduction
1. 인터넷 시대의 보안과 프라이버시
우리는 인터넷 덕분에 물리적으로 아무리 멀리 떨어져 있어도 쉽게 소통할 수 있다. 하지만, 이러한 편리함에는 대가가 따른다. 우리가 주고받는 통신 채널은 대부분 ‘공개된’ 상태이기 때문에, 누군가 악의적인 목적으로 데이터를 몰래 훔쳐보거나 위조하기가 너무 쉬워졌다.
그렇다면 이렇게 공개된 채널에서 어떻게 데이터를 안전하게 지킬 수 있을까? 이 질문에 대한 해답은 바로 암호학(Cryptography)에서 알 수 있다.
2. 암호화 (Encryption)
[대학원] 컴퓨터보안 수업 정리
Homorophic Encryption(동형암호), Public Key Encryption, Kerckhoffs의 원칙 등에 대해서 알아보자
2025/10/22

필자의 공부를 위해 [Tech Series] KT Cloud AI 에이전트 3편의 글을 필사 및 정리한 글입니다.
AI Agent의 이해와 구성요소
AI Agent란?

Google의 최신 백서(Google AI Agents White paper)에 따르면, AI Agent는 “목표를 달성하기 위해 세상을 관찰하고 주어진 도구들을 활용하여 행동하는 자율적인 AI 시스템”이다.
•
주요 특징
1.
자율성: 인간이 계속해서 개입하지 않아도 스스로 판단하고 행동할 수 있음.
2.
능동성: 해당 작업을 완료하면, 다음은 무엇을 해야 하지? 스스로 생각하며 계획을 세움. 누군가 구체적으로 지시하지 않아도, 주어진 목표를 향해 나아갈 수 있음.
3.
도구 활용 능력: 기존의 챗봇들은 대화만 할 수 있었다면, AI Agent는 실제로 외부 시스템이나 도구들을 사용해서 필요한 작업을 직접 수행할 수 있음.
AI Agent에 대해 알아보자 (feat. 협업 시스템)
AI Agent가 무엇이며, 다중 에이전트 시스템(MAS)에 대해서 알아보자
2025/08/15

24살의 도전, 28살의 마무리
24살(만 22살), 갓 전역한 대학생이 과연 사업에 도전할 수 있을까?
이 단순한 질문 하나가, 4년간의 셰어하우스 사업의 시작점이었습니다. 그저 돈을 버는 것보다, 긍정적인 ‘가치’를 세상에 남기고 싶었습니다. 또한, 저와 비슷한 대학생들에게 합리적이고 안정적인 주거 환경을 제공하고 싶다는 작은 ‘사명감’도 있었습니다.
그렇게 시작한 사업이 어느덧 4년이라는 시간을 지나, 2025년 6월을 끝으로 마무리되었습니다
’돈’이 아닌 ‘가치’를 제공하는 경험
4년간 공실률 0%, 대학생 셰어하우스 운영 마무리 및 배운 점 정리
24살(21년)부터 28살(25년)까지 약 4년 간의 셰어하우스 운영을 통해 배운 점 정리
2025/08/04



연구실에서 ‘Serveless Survey’ 논문을 읽고 세미나를 준비하는 과정에서 서버리스 함수를 실행시키는 환경 중 하나인 Container(컨테이너)에 대해서 제대로 이해하고 싶었습니다. 컨테이너를 직접 만들어보면, 확실히 이해하지 않을까 싶었는데 엄청난 영상을 찾았네요… 위의 영상을 토대로 정리한 내용이니 참고하면 좋을 것 같습니다.
컨테이너 필수 요소

Linux container vs Docker container
컨테이너를 만들기 위해서는:
•
컨테이너만을 위한 자체적인 File System(파일 시스템)
도커 없이 컨테이너(Container) 직접 만들어보자
도커 없이 리눅스에서 직접 컨테이너를 만들어보며 컨테이너를 제대로 이해하자
2025/03/23

3개의 노드를 VM으로 띄워서 쿠버네티스 클러스터를 직접 구축하고 클러스터에 Pod를 생성하는 실습까지 해보기
전체적인 그림
쿠버네티스 구조

Master Node (= Control Plane)
•
API Server
◦
역할: 주요 통신 허브로, 클라이언트와 내부 컴포넌트 간의 API 요청을 처리한다.
◦
기능: 인증, 권한 부여, API 호출 및 클러스터 상태를 etcd에 저장한다.

쿠버네티스(K8s) 클러스터 구축하기
노드 3개를 VM으로 띄워서 쿠버네티스 클러스터를 직접 구축하고 Pod를 생성하는 실습까지 해보기
2025/01/16

킬링캠프 1기, 불합격의 연속, 학부 연구생 시작, 알고리즘 코치, 학부 마지막 학기 끝
“추교현의 인생 회고록”
2021년 회고 글
2022년 회고 글
2023년 회고 글
2024년을 정리하며 2025년을 준비하고자 글을 적습니다.
- 24년 1분기 회고 & 계획
- 24년 2분기 회고 & 계획
- 24년 3분기 회고 & 계획
BYE 2024
24년 목표 및 계획 리마인드
24년 초에 세웠던 목표와 계획을 잘 지켰을까요?
2024년 단 하나의 목표는 네이버, 삼성전자 등과 같이 거대한 조직 시스템을 경험할 수 있고 체계적인 개발 문화를 배울 수 있는 곳으로 소프트웨어 엔지니어로서 취업하는 것이었습니다. 이 목표는 부족한 역량으로 인해 달성하지 못했습니다.
BYE 2024 & HELLO 2025
킬링캠프 1기, 불합격의 연속, 학부 연구생 시작, 알고리즘 코치, 학부 마지막 학기 끝
2025/01/13

디퍼런스 참여, 블록체인 해커톤 수상, 학회장 자리 물려주기, 셰어하우스 사업 2년 후기, 스타트업 퇴사, 4학년 1학기 그리고 본격적인 취업 준비 시작
“추교현의 인생 회고록”
2021년 회고 글
2022년 회고 글
2023년을 정리하며 2024년을 준비하고자 글을 적습니다.
- 2023년 1분기 회고 및 계획
- 2023년 2분기 회고 및 계획
- 2023년 3분기 회고 및 계획
BYE 2023
올해 함께 지냈던 분들 덕분에 2023년을 잘 마무리할 수 있었습니다. 정말 감사드립니다
저에게 2023년은 선택과 집중을 할 수 있었던 한 해였습니다. 올해 어떤 것을 했었는지 시간 순서대로 회고해 보도록 하겠습니다.
[23.02] DE-FERENCE
BYE 2023 & HELLO 2024
디퍼런스 참여, 블록체인 해커톤 수상, 학회장 자리 물려주기, 셰어하우스 사업 2년 후기, 스타트업 퇴사, 4학년 1학기 그리고 본격적인 취업 준비 시작
2024/01/01

짧은 창업 도전, 멋쟁이사자처럼, 블록체인 학회장, 블록체인 스타트업 입사, 블록체인 외주 프로젝트
저에게 2022년은 ‘연합 블록체인 리서치 학회인 CURG의 학회장’ 과 ‘블록체인 인프라 스타트업인 A41 입사’ 라는 굵직한 커리어를 동시에 시작하게 된 영광스러운 한 해였습니다. 후회 없이 치열한 1년을 보냈던 것 같아서 정말 뿌듯합니다
BYE 2022
KT&G 상상스타트업 캠프 6기 수료 | 21.01 - 22.03

BYE 2022 & HELLO 2023
짧은 창업 도전, 멋쟁이사자처럼, 블록체인 학회장, 블록체인 스타트업 입사, 블록체인 관련 외주
2023/01/01

전역, 셰어하우스 사업, 창업 도전, 개발 시작, 복학
“추교현의 인생 회고록”
2021년을 정리하며 2022년을 준비하고자 글을 적습니다.
BYE 2021
드디어 전역!

19년 10월 21일에 입대해서 원래는 21년 05월 08일이 실제 전역일이지만, 50일 정도 휴가를 영끌해서 조기 전역으로 21년 03월 22일에 사회로 드디어 나왔습니다!(감격...)
)BYE 2021 & HELLO 2022
전역, 셰어하우스 사업, 창업 도전, 개발 시작, 복학
2022/01/01
